






Implicit Sampling
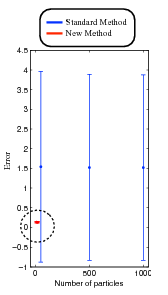
The normal standard deviation for error bars compared to the implicit sampling method. The standard method requires thousands of particles for the estimation, and the implicit sampling method requires only a few particles.
The difficulty in sampling many-dimensional probability densities on a computer is a major obstacle to progress in many fields of science, for example in economics and finance, weather forecasting, quantum field theory, and statistics. There are typically too many states to sample, most of which have a very small probability, while the location of the important states is not known in advance.
The Mathematics Group at Berkeley Lab has developed a methodology, implicit sampling, which finds unbiased high-probability samples efficiently through a variationally enhanced process, zeroing in on the high-probability regions of the sample space.
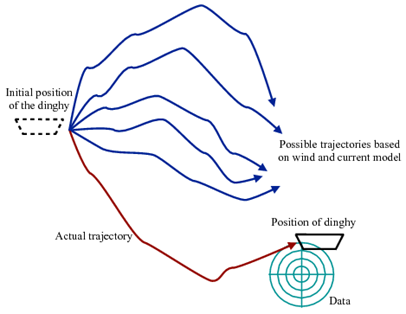
Figure 1: Example of how implicit sampling can accurately estimate the position of a dinghy (shown by the path in red) without having to trace improbable paths (shown in blue).
One major application of this methodology so far has been to the problem of data assimilation, where one is trying to make predictions on the basis of an uncertain model and a stream of noisy data (as one does, for example, in meteorology, and in economic forecasting). As an example, suppose the coast guard is trying to locate a dinghy carrying survivors from a shipwreck (see Figure 1). The previous method of calculating the dinghy’s trajectory can guess where the dinghy would be on the basis of imprecise information about wind directions and currents (this is the noisy model). Let’s say a ham radio operator has heard from someone on the dinghy, but this information is also imprecise (this is a noisy datum). How does one combine the two to find an optimal guess, without first tracing out a lot of possible paths and then finding out that most of the traced paths are in fact made unlikely by the data? Implicit sampling makes it possible to do this quickly and efficiently.
The real-life applications carried out so far include applications to oceanography, meteorology, geomagnetism, biology, and engineering. Figure 1b shows numerical results from an application to combustion, where one is trying to estimate the state of a flame from a mathematical model supplemented by noisy data. The graph shows the mean and variance of the error as a function of the number of "particles" (i.e., samples), with two estimation methods: one in wide use, and one based on implicit sampling. The latter has much smaller errors at much lower costs.
The efficient sampling of many-dimensional probability densities will have a large impact throughout science.
At Berkeley Lab, mathematics researchers are currently considering applications to quantum mechanics, statistical physics, meteorology and climate prediction, and underground hydrodynamics
About Berkeley Lab
Founded in 1931 on the belief that the biggest scientific challenges are best addressed by teams, Lawrence Berkeley National Laboratory and its scientists have been recognized with 16 Nobel Prizes. Today, Berkeley Lab researchers develop sustainable energy and environmental solutions, create useful new materials, advance the frontiers of computing, and probe the mysteries of life, matter, and the universe. Scientists from around the world rely on the Lab’s facilities for their own discovery science. Berkeley Lab is a multiprogram national laboratory, managed by the University of California for the U.S. Department of Energy’s Office of Science.
DOE’s Office of Science is the single largest supporter of basic research in the physical sciences in the United States, and is working to address some of the most pressing challenges of our time. For more information, please visit energy.gov/science.