






The Pagoda Project
 |
The Pagoda Project researches and develops cutting-edge software for implementing high-performance applications and software infrastructure under the Partitioned Global Address Space (PGAS) model. The project has been primarily funded by the Exascale Computing Project, and interacts with partner projects in industry, government and academia. |
Software
Pagoda Software Ecosystem
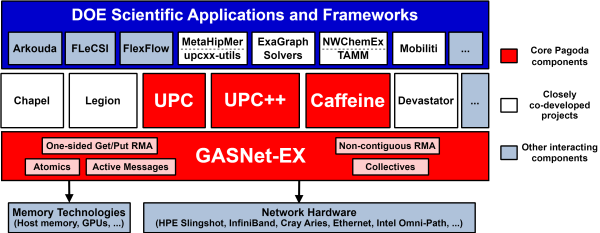
The Pagoda software ecosystem is built atop GASNet-EX, our high-performance communication portability layer. GASNet-EX supports a number of parallel programming models and frameworks developed by LBNL and other institutional partners. The Pagoda project additionally encompasses development of the UPC++ and Berkeley UPC programming model productivity layers, as well as the Caffeine Fortran parallel runtime.
GASNet-EX
GASNet is a language-independent, networking middleware layer that provides network-independent, high-performance communication primitives including Remote Memory Access (RMA) and Active Messages (AM). It has been used to implement parallel programming models and libraries such as UPC, UPC++, Co-Array Fortran, Legion, Chapel, and many others. The interface is primarily intended as a compilation target and for use by runtime library writers (as opposed to end users). The primary goals are high performance, interface portability, and expressiveness.
Overview Paper:
Dan Bonachea, Paul H. Hargrove, "GASNet-EX: A High-Performance, Portable Communication Library for Exascale", Languages and Compilers for Parallel Computing (LCPC'18), Salt Lake City, Utah, USA, October 11, 2018, LBNL-2001174, doi: 10.25344/S4QP4W
20th Anniversary Retrospective News Article:
Linda Vu,"Berkeley Lab’s Networking Middleware GASNet Turns 20: Now, GASNet-EX is Gearing Up for the Exascale Era", HPCWire (Lawrence Berkeley National Laboratory CS Area Communications), December 7, 2022, doi: 10.25344/S4BP4G
UPC++
UPC++ is a C++ library that supports Partitioned Global Address Space (PGAS) programming, and is designed to interoperate smoothly and efficiently with MPI, OpenMP, CUDA and AMTs. It leverages GASNet-EX to deliver low-overhead, fine-grained communication, including Remote Memory Access (RMA) and Remote Procedure Call (RPC).
Overview Paper:
John Bachan, Scott B. Baden, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Dan Bonachea, Paul H. Hargrove, Hadia Ahmed, "UPC++: A High-Performance Communication Framework for Asynchronous Computation", 33rd IEEE International Parallel & Distributed Processing Symposium (IPDPS'19), Rio de Janeiro, Brazil, IEEE, May 2019, doi: 10.25344/S4V88H
Caffeine
Caffeine is a parallel runtime library that aims to support Fortran compilers by providing a programming-model-agnostic Parallel Runtime Interface for Fortran (PRIF) that can be implemented atop various communication libraries. Current work is on supporting the PRIF interface with communication using GASNet-EX.
Overview Paper:
Damian Rouson, Dan Bonachea, "Caffeine: CoArray Fortran Framework of Efficient Interfaces to Network Environments", Proceedings of the Eighth Annual Workshop on the LLVM Compiler Infrastructure in HPC (LLVM-HPC2022), Dallas, Texas, USA, IEEE, November 2022, doi: 10.25344/S4459B
Berkeley UPC
Unified Parallel C (UPC) is a PGAS extension of the C programming language designed for high performance computing on large-scale parallel machines. The language provides a uniform programming model for both shared and distributed memory hardware. Berkeley UPC is a portable, high-performance implementation of the UPC language using GASNet for communication.
Overview Paper:
Wei Chen, Dan Bonachea, Jason Duell, Parry Husbands, Costin Iancu, Katherine Yelick, "A Performance Analysis of the Berkeley UPC Compiler", Proceedings of the International Conference on Supercomputing (ICS) 2003, December 1, 2003, doi: 10.1145/782814.782825
Project Participants
Current Team Members
Current and Past Contributors
- Hadia Ahmed (bodo.ai)
- John Bachan (NVIDIA)
- Scott B. Baden (UCSD, INRIA, LBNL)
- Julian Bellavita (Cornell University)
- Rob Egan (JGI, LBNL)
- Marquita Ellis (IBM)
- Sayan Ghosh (PNNL)
- Max Grossman (Georgia Tech)
- Steven Hofmeyr (LBNL)
- Khaled Ibrahim (LBNL)
- Mathias Jacquelin (Cerebras Systems)
- Bryce Adelstein Lelbach (NVIDIA)
- Colin A. MacLean (NextSilicon)
- Alexander Pöppl (TUM)
- Brad Richardson (NASA)
- Hongzhang Shan
- Brian van Straalen (LBNL)
- Daniel Waters (NVIDIA)
- Samuel Williams (LBNL)
- Katherine Yelick (LBNL)
- Yili Zheng (Google)
Publications
The Pagoda project officially began in early 2017 to continue development of the UPC++ and GASNet PGAS communication libraries under a unified umbrella. In addition to work since 2017, the list below includes a subset of publications from earlier work on GASNet (pubs), UPC (pubs) and the predecessor to the UPC++ (pubs) library written by many of the same group members under previous project funding. Consult linked project pages for complete publication history.
2025
Damian Rouson, Zhe Bai, Dan Bonachea, Baboucarr Dibba, Ethan Gutmann, Katherine Rasmussen, David Torres, Jordan Welsman, Yunhao Zhang, "Cloud microphysics training and aerosol inference with the Fiats deep learning library", UCAR–SEA Improving Scientific Software Conference (ISS25), August 2025, doi: 10.25344/S4QS3J
This notebook presents two atmospheric sciences demonstration applications in the Fiats deep learning software repository. The first, train-cloud-microphysics, trains a neural-network cloud microphysics surrogate model that has been integrated into the Berkeley Lab fork of the Intermediate Complexity Atmospheric Research (ICAR) model. The second, infer-aerosol, performs parallel inference with an aerosol dynamics surrogate pretrained in PyTorch using data from the Energy Exascale Earth System Model (E3SM). This notebook presents the program statements involved in using Fiats for aerosol inference and microphysics training. In order to also give the interested reader direct experience with using Fiats for these purposes, the notebook details how to run two simpler example programs that serve as representative proxies for the demonstration applications. Both proxies are also example programs in the Fiats repository. The microphysics training proxy is a self-contained example requiring no input files. The aerosol inference proxy uses a pretrained aerosol model stored in the Fiats JavaScript Object Notation (JSON) file format and hyperlinked into this notebook for downloading, importing, and using to perform batch inference calculations with Fiats.
Brandon Cook, Damian Rouson, Dan Bonachea, "US04: Non-blocking Collective Subroutines", JTC1/SC22/WG5 ISO Fortran Standards document (WG5/N2245), June 2025,
Proposal for adding explicitly non-blocking collective subroutines to the worklist for Fortran 202Y.
Reinhold Bader, Dan Bonachea, HPC, "DIN1: Collectives over a specified team, req/spec/syntax/edits", INCITS/US Fortran Programming Language Standards Technical Committee (J3/25-127r1), June 2025,
This paper contains formal requirements, specifications, syntax and edits for Fortran 202Y proposal DIN1, collectives over a specified team.
Gary Klimowicz, Dan Bonachea, Patrick Fasano, Steve Lionel, "Formal specifications for the Fortran preprocessor (FPP)", INCITS/US Fortran Programming Language Standards Technical Committee (J3/25-142r2), June 2025,
Damian Rouson, Zhe Bai, Dan Bonachea, Kareem Ergawy, Ethan Gutmann, Michael Klemm, Katherine Rasmussen, Brad Richardson, Sameer Shende, David Torres, Yunhao Zhang, "Automatically parallelizing batch inference on deep neural networks using Fiats and Fortran 2023 `do concurrent`", Fifth International Workshop on Computational Aspects of Deep Learning (CADL), June 2025, doi: 10.25344/S4VG6T
This paper introduces novel programming strategies that leverage features of the Fortran 2023 standard of the International Standards Organization (ISO) to automatically parallelize computations on deep neural networks. The paper focuses on the interplay of object-oriented, parallel, and functional programming paradigms in the Fiats deep learning library. We demonstrate how several infrequently used language features play a role in enabling efficient, parallel execution. Specifically, the ability to explicitly declare that a procedure is pure facilitates inference in the context of the language’s loop-parallelism construct `do concurrent`. Also, explicitly prohibiting the overriding of a parent type’s type-bound procedures eliminates the need for dynamic dispatch in performance-critical code. Finally, this paper uses batch inference calculations on a neural network surrogate for atmospheric aerosol dynamics to demonstrate that LLVM Flang compiler’s automatic parallelization of `do concurrent` achieves roughly the same performance and scalability as achieved by OpenMP compiler directives. We also demonstrate that double-precision inference costs 37–72% longer runtime than default-real precision with most values in the range 57-60%.
Brandon Cook, Dan Bonachea, "Requirements for US20: Local Prefix Operation Intrinsics", INCITS/US Fortran Programming Language Standards Technical Committee (J3/25-145r1), June 2025,
Scan, or prefix reduction, operations are fundamental building blocks in parallel algorithms and data manipulation tasks. The SCAN and CO_SCAN proposal (J3/23-235r2) received "mixed support" at a previous meeting, and prospective work items, including prefix reduction operations, were "conditionally accepted" at the 2024 meeting, pending further discussion. They were again discussed at the February 2025 WG5 meeting, and subsequently promoted to "accepted" work item US20 via WG5 letter ballot in May 2025 (WG5/N-2239). The result of the WG5 vote was 20 yes 5 no and 1 undecided with several informative comments.
This document focuses on requirements exclusively for the local prefix reduction variant, refining previous concepts based on community and WG5 feedback. By focusing exclusively on the local variant our aim is to allow consideration independent of the closely related but distinct collective subroutines. We do however revisit use cases briefly for clarity as we are now addressing the two variants separately.
Brandon Cook, Dan Bonachea, "Requirements for US20 collective subroutines for prefix operations", INCITS/US Fortran Programming Language Standards Technical Committee (J3/25-144r1), June 2025,
Scan, or prefix reduction, operations are fundamental building blocks in parallel algorithms and data manipulation tasks. The original `SCAN` and `CO_SCAN` proposal received "mixed support" , and prefix reduction operations were subsequently "conditionally accepted" as a prospective work item for F202Y at the 2024 WG5 meeting, pending further discussion and refinement. They were again discussed at the February 2025 WG5 meeting, and subsequently promoted to "accepted" work item US20 via WG5 letter ballot in May 2025 (WG5/N-2239). The result of the WG5 vote was 20 yes 5 no and 1 undecided with several informative comments.
This paper focuses exclusively on requirements for the collective subroutine variant refining previous concepts based on community and WG5 feedback. Our aim is to allow consideration independent of the closely related but distinct local intrinsics. We briefly revisit use cases as we are now addressing the two variants separately.
Paul H. Hargrove, Dan Bonachea, "Investigation into the Performance Benefits of Exposing Network Backpressure in UPC++ and GASNet-EX", Lawrence Berkeley National Laboratory Technical Report, May 2025, LBNL 2001668, doi: 10.25344/S4088R
This document is a brief summary of the research, and supporting development efforts, conducted by the project "Investigation into Improving Dynamic Adaptivity to System-Level Asynchrony in UPC++". We tested the hypothesis "The UPC++ and GASNet-EX runtimes can expose information from the network stack that enables applications to dynamically adapt to congestion, improving total throughput". We present experimental results from both a microbenchmark and an application benchmark that support this hypothesis.
Katherine Rasmussen, Damian Rouson, Dan Bonachea, Julienne + Assert == Correctness-Checking for Functional Fortran, Improving Scientific Software Conference, April 2025, doi: 10.25344/S4401K
The agile software development practice of test-driven development (TDD) advocates unit testing as an essential driver of software design and construction. In TDD, tests of individual units of software (e.g., procedures) serve documentation and verification roles. As documentation, tests specify the behaviors required for code correctness. Executing a suite of tests verifies that the actual behaviors satisfy the documented requirements. As inspired by the Veggies and Garden unit testing frameworks for modern Fortran, the more lightweight Julienne framework uses the Template Method pattern to report serial or parallel test results in the form of a specification (https://go.lbl.gov/julienne). As such, Julienne’s test output names the test subject (e.g., a class or type-bound procedure), the expected behavior, the test outcome (pass or fail), and provides diagnostic information if a test fails.
The use of Julienne centers around users defining a test in the form of a non-abstract child type that extends Julienne’s abstract test_t derived type. The user’s child type thus inherits an obligation to define type-bound procedures that name the subject of the test and provide the test results. As a template method, test_t’s type-bound “report” procedure invokes the user’s procedures by referencing the aforementioned deferred bindings and reporting on the collective success or failure across multiple images (processes) in programs that use Fortran’s multi-image parallel programming features.
Working from the example test suite in the Julienne repository, attendees will learn how to write and run a simple test suite, including how to use Julienne’s string-handling for producing rich diagnostic information from a failing test. Attendees will also see examples of Julienne’s use in other Berkeley Lab software projects such as the Fiats deep learning library and Matcha T-cell motility simulator.
Attendees will also learn a functional programming pattern developed and used by the Berkeley Lab Fortran presenters. Functional programming centers around the definition of pure procedures that are free of side effects, including file input and output. To supplement the material on external verification via unit tests, this tutorial will also introduce our Assert utility library and Assert’s use for runtime correctness-checking inside procedures (https://go.lbl.gov/assert). Attendees will learn how Assert addresses a common reason developers cite for not writing pure procedures: a desire to produce diagnostic output when debugging code. We posit that most developers seek output to verify an expectation about data and that such expectations can be stated in assertions that take the form of logical expressions. Attendees will learn how Assert empowers developers to obtain rich, customized diagnostic information through character stop codes when an assertion fails, resulting in error termination. Attendees will also learn how to use Assert in such a way that guarantees zero runtime overhead by automatically eliminating assertions in production builds of user software.
Dan Bonachea, Katherine Rasmussen, Brad Richardson, Damian Rouson, "Caffeine: A parallel runtime library for supporting modern Fortran compilers", Journal of Open Source Software, edited by Daniel S. Katz, March 29, 2025, 10(107), doi: 10.21105/joss.07895
The Fortran programming language standard added features supporting single-program, multiple data (SPMD) parallel programming and loop parallelism beginning with Fortran 2008. In Fortran, SPMD programming involves the creation of a fixed number of images (instances) of a program that execute asynchronously in shared or distributed memory, except where a program uses specific synchronization mechanisms. Fortran’s “coarray’’ distributed data structures offer a subscripted, multidimensional array notation defining a partitioned global address space (PGAS). One image can use this notation for one-sided access to another image’s slice of a coarray.
The CoArray Fortran Framework of Efficient Interfaces to Network Environments (Caffeine) provides a runtime library that supports Fortran’s SPMD features. Caffeine implements inter-process communication by building atop the GASNet-EX exascale networking middleware library. Caffeine is the first implementation of the compiler- and runtime-agnostic Parallel Runtime Interface for Fortran (PRIF) specification. Any compiler that targets PRIF can use any runtime that supports PRIF. Caffeine supports researching the novel approach of writing most of a compiler’s parallel runtime library in the language being compiled: Caffeine is primarily implemented using Fortran’s non-parallel features, with a thin C-language layer that invokes the external GASNet-EX communication library. Exploring this approach in open source lowers a barrier to contributions from the compiler’s users: Fortran programmers. Caffeine also facilitates research such as investigating various optimization opportunities that exploit specific hardware such as shared memory or specific interconnects.
Damian Rouson, What Happens to a Dream Deferred? Chasing Language-Based Parallel Programming for HPC and AI, SIAM Conference on Computational Science and Engineering (CSE25), March 5, 2025, doi: 10.25344/S47S36
In 1951, Harlem Renaissance poet Langston Hughes asked this talk's titular question at the outset of a poem entitled "Harlem." Six years later, IBM mathematician John Backus developed Fortran, the world's first widely used high-level programming language. Backus later explored functional programming and highlighted the functional style in his Turing Award lecture in 1977, a year that also demarcates what one might consider the end of the classical era of Fortran. Building on a vision the presenter first conceived around the turn of the 21st century while teaching in Harlem, this talk will demonstrate how Fortran 2023 can finally deliver on Backus's functional programming dream in traditional high-performance computing (HPC) domains such as partial differential equation (PDE) solvers and in emerging domains such as artificial intelligence (AI). For PDE solvers, the talk will describe language facilities for asynchronously evaluating expressions that apply discrete, parallel, purely-functional differential operators to software abstractions that model continuous mathematical abstractions. For AI, the talk will demonstrate that Fortran's native concurrent loop iterations can combine with side-effect-free, pure procedures to facilitate automatically parallelizing deep-learning inference and training algorithms on processors and accelerators. The talk will provide updates on an ongoing effort by Berkeley Lab's Fortran team to realize this dream by through our work at multiple levels in the software stack, including applications, compiler runtime libraries, and networking middleware. Along the way, the talk will highlight ways in which programs promoting inclusivity in science facilitated significant aspects of the presented work.
SIAM Conference on Computational Science and Engineering (CSE25)
Dan Bonachea, HPC, "F202Y feature request: collectives over a specified team", INCITS/US Fortran Programming Language Standards Technical Committee (J3/25-125r1), February 2025,
As of Fortran 2023, the collective subroutine intrinsics (CO_BROADCAST, CO_MAX, CO_MIN, CO_REDUCE, and CO_SUM) may only be executed over the current team, as defined by the CHANGE TEAM construct. This becomes very awkward when one needs to execute such a collective over an ancestor team; because there is no way to directly express that without closing the CHANGE TEAM construct, and invoking END TEAM may have undesired side-effects such as deallocating team-specific coarrays. It would also be convenient to allow collectives directly over a child team without forcing the synchronization side effects associated with a CHANGE TEAM to that child team.
The collective subroutines of Fortran should support execution in a specified team that is not the current team.
Paper PASSED by roll call vote at INCITS/US Fortran Programming Language Standards Technical Committee meeting #235
Gary Klimowicz, Dan Bonachea, Aury Shafran, "Fortran preprocessor requirements", INCITS/US Fortran Programming Language Standards Technical Committee (J3/25-114r2), February 2025,
Many existing Fortran projects make extensive use of C preprocessor directives and macro expansion, despite the lack of an FPP standard. This is usually done to tailor the code to specific environments, such as target compilers or machines. Unfortunately, more complex use cases fail to be portable between different implementations. This is enough of a problem that WG 5 raised this as the number 2 issue to address in Fortran 202y, behind generics. This is not a new problem, as evidenced by the J3 discussions from the mid 1990s. The introduction of CoCo in Fortran 95 did not solve the problem, either, because it was not a mandatory part of the standard and because it was not compatible with the preprocessor syntax used by many existing Fortran projects. This document attempts to define the requirements for a mandatory Fortran preprocessor based on the preprocessor syntax already in common use today. The guiding principle is to promote Fortran program portability by defining consistent syntax and semantics of a useful subset of CPP. Some FPP behavior will be slightly different from CPP, in order to accommodate some Fortran idiosyncrasies. A major overarching goal of this effort is to standardize de facto current practice for preprocessing in Fortran compilers and code. It is the standard's responsibility to standardize syntax in order to settle minor divergences that have arisen amongst pre-standard FPP implementations, to the detriment of portability for end users.
Paper PASSED by unanimous consent at INCITS/US Fortran Programming Language Standards Technical Committee meeting #235
2024
Dan Bonachea, Katherine Rasmussen, Brad Richardson, Damian Rouson, "Parallel Runtime Interface for Fortran (PRIF) Specification, Revision 0.5", Lawrence Berkeley National Laboratory Tech Report, December 2024, LBNL 2001636, doi: 10.25344/S4CG6G
This document specifies an interface to support the parallel features of Fortran, named the Parallel Runtime Interface for Fortran (PRIF). PRIF is a proposed solution in which the runtime library is primarily responsible for implementing coarray allocation, deallocation and accesses, image synchronization, atomic operations, events, teams and collective subroutines. In this interface, the compiler is responsible for transforming the invocation of Fortran-level parallel features into procedure calls to the necessary PRIF subroutines. The interface is designed for portability across shared- and distributed-memory machines, different operating systems, and multiple architectures. Implementations of this interface are intended as an augmentation for the compiler's own runtime library. With an implementation-agnostic interface, alternative parallel runtime libraries may be developed that support the same interface. One benefit of this approach is the ability to vary the communication substrate. A central aim of this document is to define a parallel runtime interface in standard Fortran syntax, which enables us to leverage Fortran to succinctly express various properties of the procedure interfaces, including argument attributes.
Dan Bonachea, Katherine Rasmussen, Brad Richardson, Damian Rouson, "Parallel Runtime Interface for Fortran (PRIF): A Multi-Image Solution for LLVM Flang", Tenth Workshop on the LLVM Compiler Infrastructure in HPC (LLVM-HPC2024), Atlanta, Georgia, USA, IEEE, November 2024, doi: 10.25344/S4N017
- Download File: LLVM-HPC24_PRIF_Slides.pdf (pdf: 975 KB)
Fortran compilers that provide support for Fortran’s native parallel features often do so with a runtime library that depends on details of both the compiler implementation and the communication library, while others provide limited or no support at all. This paper introduces a new generalized interface that is both compiler- and runtime-library-agnostic, providing flexibility while fully supporting all of Fortran’s parallel features. The Parallel Runtime Interface for Fortran (PRIF) was developed to be portable across shared- and distributed-memory systems, with varying operating systems, toolchains and architectures. It achieves this by defining a set of Fortran procedures corresponding to each of the parallel features defined in the Fortran standard that may be invoked by a Fortran compiler and implemented by a runtime library. PRIF aims to be used as the solution for LLVM Flang to provide parallel Fortran support. This paper also briefly describes our PRIF prototype implementation: Caffeine.
Damian Rouson, Baboucarr Dibba, Katherine Rasmussen, Brad Richardson, David Torres, Yunhao Zhang, Ethan Gutmann, Kareem Ergawy, Michael Klemm, Sameer Shende, Just Write Fortran: Experiences with a Language-Based Alternative to MPI+X, Talk at IEEE/ACM Parallel Applications Workshop, Alternatives To MPI+X (PAW-ATM), November 2024, doi: 10.25344/S4H88D
Fortran 2023, with its "do concurrent" and coarray parallel programming features, displaces many uses of extra-language parallel programming models such as MPI, OpenMP, and OpenACC. The Cray, Intel, LFortran, LLVM, and NVIDIA compilers automatically parallelize do concurrent in shared memory. The Cray, Intel, and GNU compilers support coarrays in shared- and distributed-memory, while the NAG compiler supports coarrays in shared memory. Thus, language-based parallelism is emerging as a portable alternative to MPI+X.
This talk will present experiences with automatic "do concurrent" parallelization in the deep learning library Inference-Engine and coarray communication in the Intermediate Complexity Atmospheric Research (ICAR), respectively.
Katherine Rasmussen, Damian Rouson, Dan Bonachea, Brad Richardson, "A Full-Stack Exploration of Language-Based Parallelism in Fortran 2023", Poster at CARLA2024: Latin America High Performance Computing Conference, September 30, 2024, doi: 10.25344/S4RP5K
This poster explores native parallel features in Fortran 2023 through the lens of supporting applications with libraries, compilers, and parallel runtimes. The language revision informally named Fortran 2008 introduced parallelism in the form of Single Program Multiple Data (SPMD) execution with two broad feature sets: (1) loop-level parallelism via do concurrent and (2) a Partitioned Global Address Space (PGAS) comprised of distributed “coarray” data structures. Fortran’s native parallelism has demonstrated high performance [1] and reduced the burden of inserting what sometimes amounts to more directives than code. Several compilers support both feature sets, typically by translating do concurrent into serial do loops annotated by parallel directives and by translating SPMD/PGAS features into direct calls to a communication library. Our research focuses primarily on two questions: (1) can the compiler’s parallel runtime library be developed in the language being compiled (Fortran) and (2) can we define an interface to the runtime that liberates compilers from being hardwired to one runtime and vice versa. We are answering these questions by developing the Parallel Runtime Interface for Fortran (PRIF) [2] and the Co-Array Fortran Framework of Efficient Interfaces to Network Environments (Caffeine) [3]. Caffeine is initially targeting adoption by LLVM Flang, a new open-source Fortran compiler developed by a broad community in industry, academia, and government labs. We are also exploring the use of these features in Inference-Engine, a deep learning library designed to facilitate neural network training and inference for high-performance computing applications written in modern Fortran.
Leyba K, Hofmeyr S, Forrest S, Cannon J, Moses M, "SIMCoV-GPU: Accelerating an Agent-Based Model for Exascale", HPDC '24, August 30, 2024, doi: 10.1145/3625549.3658692
Dan Bonachea, Katherine Rasmussen, Brad Richardson, Damian Rouson, "Parallel Runtime Interface for Fortran (PRIF) Specification, Revision 0.4", Lawrence Berkeley National Laboratory Tech Report, July 12, 2024, LBNL 2001604, doi: 10.25344/S4WG64
This document specifies an interface to support the parallel features of Fortran, named the Parallel Runtime Interface for Fortran (PRIF). PRIF is a proposed solution in which the runtime library is responsible for coarray allocation, deallocation and accesses, image synchronization, atomic operations, events, and teams. In this interface, the compiler is responsible for transforming the invocation of Fortran-level parallel features into procedure calls to the necessary PRIF procedures. The interface is designed for portability across shared- and distributed-memory machines, different operating systems, and multiple architectures. Implementations of this interface are intended as an augmentation for the compiler’s own runtime library. With an implementation-agnostic interface, alternative parallel runtime libraries may be developed that support the same interface. One benefit of this approach is the ability to vary the communication substrate. A central aim of this document is to define a parallel runtime interface in standard Fortran syntax, which enables us to leverage Fortran to succinctly express various properties of the procedure interfaces, including argument attributes.
Dan Bonachea, Katherine Rasmussen, Brad Richardson, Damian Rouson, Parallel Runtime Interface for Fortran (PRIF): A Compiler/Runtime-Library Agnostic Interface to Support the Parallel Features of Fortran 2023, Platform for Advanced Scientific Computing (PASC) Modern Fortran Minisymposium, June 5, 2024,
- Download File: PRIF-PASC24.pdf (pdf: 1.6 MB)
Fortran 2023 natively supports single-program, multiple-data parallel programming with a partitioned global address space and collective subroutines, synchronization, atomics, locks, and more. Each of the four actively developed compilers that support Fortran’s parallel features uses its own parallel runtime library. The Parallel Runtime Interface for Fortran (PRIF) proposes to liberate compiler development from reliance on a single runtime and empower runtime developers to support more than one compiler. PRIF also aims to broaden the community of runtime developers to include the Fortran compiler’s users: Fortran programmers. PRIF does so by specifying the interface in Fortran, which makes it attractive to write the parallel runtime library in Fortran. Additionally, PRIF has been designed to be portable across both shared and distributed memory, varying architectures, as well as different operating systems. In this talk, I will describe the motivation behind the development of PRIF, describe the design of the interface itself and the benefits of adopting it. I will also provide a brief status report on the first PRIF implementation: Caffeine.
Damian Rouson, What Happens to a Dream Deferred? Chasing Automatic Offloading in Fortran 2023, Keynote Talk at the Nineteenth International Workshop on Automatic Performance Tuning (iWAPT 2024), May 31, 2024,
- Download File: iWAPT-2024-Keynote.pdf (pdf: 6.7 MB)
In 1951, Harlem Renaissance poet Langston Hughes asked this talk's titular question at the outset of a poem entitled "Harlem." Six years later, IBM mathematician John Backus developed Fortran, the world's first widely used high-level programming language. Backus went on to explore functional programming and to highlight the functional style in his Turing Award lecture in 1977, a year that also demarcates what one might consider the end of the classical era of Fortran. This talk will demonstrate how modern Fortran began to deliver on Backus's functional programming dream, starting with pure procedures in the 1995 standard. The talk will further demonstrate how this style culminated in a powerful and flexible facility for expressing independent iterations via the "do concurrent" construct, which the Fortran standard committee included in Fortran 2008 with the intention to facilitate automatic Graphics Processing Unit (GPU) programming. Fortran 2008 was published in 2010, but it took another decade for compilers to deliver on the promise of automatic GPU offloading. This talk will detail the trials and tribulations of Berkeley Lab's Fortran team in chasing the automatic offloading dream in our Inference-Engine deep learning library and Matcha high-performance computing (HPC) application.
Dan Bonachea, Paul H. Hargrove, "GASNet-EX Specification Collection, Revision 2024.5.0", Lawrence Berkeley National Laboratory Tech Report, May 2024, LBNL 2001595, doi: 10.25344/S4160B
GASNet-EX is a portable, open-source, high-performance communication library designed to efficiently support the networking requirements of PGAS runtime systems and other alternative models in emerging exascale systems. It provides network-independent, high-performance communication primitives including Remote Memory Access (RMA) and Active Messages (AM). GASNet-EX is an evolution of the popular GASNet communication system, building upon over 20 years of lessons learned, and the primary goals are high performance, interface portability, and expressiveness. The library has been used to implement parallel programming models and libraries such as UPC, UPC++, Fortran coarrays, Legion, Chapel, and many others.
This anthology collects together the four separate volumes that currently comprise the GASNet-EX specification, as of the 2024.5.0 release of GASNet-EX.
Dan Bonachea, Katherine Rasmussen, Brad Richardson, Damian Rouson, "Parallel Runtime Interface for Fortran (PRIF) Specification, Revision 0.3", Lawrence Berkeley National Laboratory Tech Report, May 3, 2024, LBNL 2001590, doi: 10.25344/S4501W
This document specifies an interface to support the parallel features of Fortran, named the Parallel Runtime Interface for Fortran (PRIF). PRIF is a proposed solution in which the runtime library is responsible for coarray allocation, deallocation and accesses, image synchronization, atomic operations, events, and teams. In this interface, the compiler is responsible for transforming the invocation of Fortran-level parallel features into procedure calls to the necessary PRIF procedures. The interface is designed for portability across shared- and distributed-memory machines, different operating systems, and multiple architectures. Implementations of this interface are intended as an augmentation for the compiler’s own runtime library. With an implementation-agnostic interface, alternative parallel runtime libraries may be developed that support the same interface. One benefit of this approach is the ability to vary the communication substrate. A central aim of this document is to define a parallel runtime interface in standard Fortran syntax, which enables us to leverage Fortran to succinctly express various properties of the procedure interfaces, including argument attributes.
2023
Damian Rouson, Brad Richardson, Dan Bonachea, Katherine Rasmussen, "Parallel Runtime Interface for Fortran (PRIF) Design Document, Revision 0.2", Lawrence Berkeley National Laboratory Tech Report, December 20, 2023, LBNL 2001563, doi: 10.25344/S4DG6S
This design document proposes an interface to support the parallel features of Fortran, named the Parallel Runtime Interface for Fortran (PRIF). PRIF is a proposed solution in which the runtime library is responsible for coarray allocation, deallocation and accesses, image synchronization, atomic operations, events, and teams. In this interface, the compiler is responsible for transforming the invocation of Fortran-level parallel features into procedure calls to the necessary PRIF procedures. The interface is designed for portability across shared- and distributed-memory machines, different operating systems, and multiple architectures. Implementations of this interface are intended as an augmentation for the compiler’s own runtime library. With an implementation-agnostic interface, alternative parallel runtime libraries may be developed that support the same interface. One benefit of this approach is the ability to vary the communication substrate. A central aim of this document is to define a parallel runtime interface in standard Fortran syntax, which enables us to leverage Fortran to succinctly express various properties of the procedure interfaces, including argument attributes.
Dan Bonachea, Amir Kamil, "UPC++ v1.0 Specification, Revision 2023.9.0", Lawrence Berkeley National Laboratory Tech Report LBNL-2001561, December 2023, doi: 10.25344/S4J592
UPC++ is a C++ library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. The key communication facilities in UPC++ are one-sided Remote Memory Access (RMA) and Remote Procedure Call (RPC). All communication operations are syntactically explicit and default to non-blocking; asynchrony is managed through the use of futures, promises and continuation callbacks, enabling the programmer to construct a graph of operations to execute asynchronously as high-latency dependencies are satisfied. A global pointer abstraction provides system-wide addressability of shared memory, including host and accelerator memories. The parallelism model is primarily process-based, but the interface is thread-safe and designed to allow efficient and expressive use in multi-threaded applications. The interface is designed for extreme scalability throughout, and deliberately avoids design features that could inhibit scalability.
John Bachan, Scott B. Baden, Dan Bonachea, Johnny Corbino, Max Grossman, Paul H. Hargrove, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, Daniel Waters, "UPC++ v1.0 Programmer’s Guide, Revision 2023.9.0", Lawrence Berkeley National Laboratory Tech Report LBNL-2001560, December 2023, doi: 10.25344/S4P01J
UPC++ is a C++ library that supports Partitioned Global Address Space (PGAS) programming. It is designed for writing efficient, scalable parallel programs on distributed-memory parallel computers. The key communication facilities in UPC++ are one-sided Remote Memory Access (RMA) and Remote Procedure Call (RPC). The UPC++ control model is single program, multiple-data (SPMD), with each separate constituent process having access to local memory as it would in C++. The PGAS memory model additionally provides one-sided RMA communication to a global address space, which is allocated in shared segments that are distributed over the processes. UPC++ also features Remote Procedure Call (RPC) communication, making it easy to move computation to operate on data that resides on remote processes. UPC++ was designed to support exascale high-performance computing, and the library interfaces and implementation are focused on maximizing scalability. In UPC++, all communication operations are syntactically explicit, which encourages programmers to consider the costs associated with communication and data movement. Moreover, all communication operations are asynchronous by default, encouraging programmers to seek opportunities for overlapping communication latencies with other useful work. UPC++ provides expressive and composable abstractions designed for efficiently managing aggressive use of asynchrony in programs. Together, these design principles are intended to enable programmers to write applications using UPC++ that perform well even on hundreds of thousands of cores.
Julian Bellavita, Mathias Jacquelin, Esmond G. Ng, Dan Bonachea, Johnny Corbino, Paul H. Hargrove, "symPACK: A GPU-Capable Fan-Out Sparse Cholesky Solver", 2023 IEEE/ACM Parallel Applications Workshop, Alternatives To MPI+X (PAW-ATM'23), ACM, November 13, 2023, doi: 10.1145/3624062.3624600
Sparse symmetric positive definite systems of equations are ubiquitous in scientific workloads and applications. Parallel sparse Cholesky factorization is the method of choice for solving such linear systems. Therefore, the development of parallel sparse Cholesky codes that can efficiently run on today’s large-scale heterogeneous distributed-memory platforms is of vital importance. Modern supercomputers offer nodes that contain a mix of CPUs and GPUs. To fully utilize the computing power of these nodes, scientific codes must be adapted to offload expensive computations to GPUs.
We present symPACK, a GPU-capable parallel sparse Cholesky solver that uses one-sided communication primitives and remote procedure calls provided by the UPC++ library. We also utilize the UPC++ "memory kinds" feature to enable efficient communication of GPU-resident data. We show that on a number of large problems, symPACK outperforms comparable state-of-the-art GPU-capable Cholesky factorization codes by up to 14x on the NERSC Perlmutter supercomputer.
Michelle Mills Strout, Damian Rouson, Amir Kamil, Dan Bonachea, Jeremiah Corrado, Paul H. Hargrove, Introduction to High-Performance Parallel Distributed Computing using Chapel, UPC++ and Coarray Fortran, Tutorial at the International Conference for High Performance Computing, Networking, Storage, and Analysis (SC23), November 12, 2023,
A majority of HPC system users utilize scripting languages such as Python to prototype their computations, coordinate their large executions, and analyze the data resulting from their computations. Python is great for these many uses, but it frequently falls short when significantly scaling up the amount of data and computation, as required to fully leverage HPC system resources. In this tutorial, we show how example computations such as heat diffusion, k-mer counting, file processing, and distributed maps can be written to efficiently leverage distributed computing resources in the Chapel, UPC++, and Fortran parallel programming models.
The tutorial is targeted for users with little-to-no parallel programming experience, but everyone is welcome. A partial differential equation example will be demonstrated in all three programming models. That example and others will be provided to attendees in a virtual environment. Attendees will be shown how to compile and run these programming examples, and the virtual environment will remain available to attendees throughout the conference, along with Slack-based interactive tech support.
Come join us to learn about some productive and performant parallel programming models!
A. Dubey, T. Ben-Nun, B. L. Chamberlain, B. R. de Supinski, D. Rouson, "Performance on HPC Platforms Is Possible Without C++", Computing in Science & Engineering, September 2023, 25 (5):48-52, doi: 10.1109/MCSE.2023.3329330
Computing at large scales has become extremely challenging due to increasing heterogeneity in both hardware and software. More and more scientific workflows must tackle a range of scales and use machine learning and AI intertwined with more traditional numerical modeling methods, placing more demands on computational platforms. These constraints indicate a need to fundamentally rethink the way computational science is done and the tools that are needed to enable these complex workflows. The current set of C++-based solutions may not suffice, and relying exclusively upon C++ may not be the best option, especially because several newer languages and boutique solutions offer more robust design features to tackle the challenges of heterogeneity. In June 2023, we held a mini symposium that explored the use of newer languages and heterogeneity solutions that are not tied to C++ and that offer options beyond template metaprogramming and Parallel. For for performance and portability. We describe some of the presentations and discussion from the mini symposium in this article.
"Pagoda Updates PGAS Programming With Scalable Data Structures And Aggressively Asynchronous Communication", Rob Farber, Exascale Computing Project News, August 28, 2023, doi: 10.25344/S4SP4H
Riley R, Bowers RM, Camargo AP, Campbell A, Egan R, Eloe-Fadrosh EA, Foster B, Hofmeyr S, Huntemann M, Kellom M, Kimbrel JA, Oliker L, Yelick K, Pett-Ridge J, Salamov A, Varghese NJ, Clum A, "Terabase-Scale Coassembly of a Tropical Soil Microbiome", Microbiology Spectrum, August 17, 2023, doi: 10.1128/SPECTRUM.00200-23
Michelle Mills Strout, Damian Rouson, Amir Kamil, Dan Bonachea, Jeremiah Corrado, Paul H. Hargrove, Introduction to High-Performance Parallel Distributed Computing using Chapel, UPC++ and Coarray Fortran (CUF23), ECP/NERSC/OLCF Tutorial, July 2023,
A majority of HPC system users utilize scripting languages such as Python to prototype their computations, coordinate their large executions, and analyze the data resulting from their computations. Python is great for these many uses, but it frequently falls short when significantly scaling up the amount of data and computation, as required to fully leverage HPC system resources. In this tutorial, we show how example computations such as heat diffusion, k-mer counting, file processing, and distributed maps can be written to efficiently leverage distributed computing resources in the Chapel, UPC++, and Fortran parallel programming models. This tutorial should be accessible to users with little-to-no parallel programming experience, and everyone is welcome. A partial differential equation example will be demonstrated in all three programming models along with performance and scaling results on big machines. That example and others will be provided in a cloud instance and Docker container. Attendees will be shown how to compile and run these programming examples, and provided opportunities to experiment with different parameters and code alternatives while being able to ask questions and share their own observations. Come join us to learn about some productive and performant parallel programming models!
Secondary tutorial sites by event sponsors:
Paul H. Hargrove, PGAS Programming Models: My 20-year Perspective, Keynote for 10th Annual Chapel Implementers and Users Workshop (CHIUW 2023), June 2, 2023, doi: 10.25344/S4K59C
Paul H. Hargrove has been involved in the world of Partitioned Global Address Space (PGAS) programming models since 1999, before he knew such a thing existed. Early involvement in the GASNet communications library as used in implementations of UPC, Titanium and Co-array Fortran convinced Paul that one could have productivity and performance without sacrificing one for the other. Since then he has been among the apostates who work to overturn the belief that message-passing is the only (or best) way to program for High-Performance Computing (HPC). Paul has been fortunate to witness the history of the PGAS community through several rare opportunities, including interactions made possible by the wide adoption of GASNet and through operating a PGAS booth at the annual SC conferences from 2007 to 2017. In this talk, Paul will share some highlights of his experiences across 24 years of PGAS history. Among these is the DARPA High Productivity Computing Systems (HPCS) project which helped give birth to Chapel.
Dan Bonachea, Amir Kamil, "UPC++ v1.0 Specification, Revision 2023.3.0", Lawrence Berkeley National Laboratory Tech Report, March 31, 2023, LBNL 2001516, doi: 10.25344/S46W2J
UPC++ is a C++ library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. The key communication facilities in UPC++ are one-sided Remote Memory Access (RMA) and Remote Procedure Call (RPC). All communication operations are syntactically explicit and default to non-blocking; asynchrony is managed through the use of futures, promises and continuation callbacks, enabling the programmer to construct a graph of operations to execute asynchronously as high-latency dependencies are satisfied. A global pointer abstraction provides system-wide addressability of shared memory, including host and accelerator memories. The parallelism model is primarily process-based, but the interface is thread-safe and designed to allow efficient and expressive use in multi-threaded applications. The interface is designed for extreme scalability throughout, and deliberately avoids design features that could inhibit scalability.
John Bachan, Scott B. Baden, Dan Bonachea, Johnny Corbino, Max Grossman, Paul H. Hargrove, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, Daniel Waters, "UPC++ v1.0 Programmer’s Guide, Revision 2023.3.0", Lawrence Berkeley National Laboratory Tech Report, March 30, 2023, LBNL 2001517, doi: 10.25344/S43591
UPC++ is a C++ library that supports Partitioned Global Address Space (PGAS) programming. It is designed for writing efficient, scalable parallel programs on distributed-memory parallel computers. The key communication facilities in UPC++ are one-sided Remote Memory Access (RMA) and Remote Procedure Call (RPC). The UPC++ control model is single program, multiple-data (SPMD), with each separate constituent process having access to local memory as it would in C++. The PGAS memory model additionally provides one-sided RMA communication to a global address space, which is allocated in shared segments that are distributed over the processes. UPC++ also features Remote Procedure Call (RPC) communication, making it easy to move computation to operate on data that resides on remote processes.
UPC++ was designed to support exascale high-performance computing, and the library interfaces and implementation are focused on maximizing scalability. In UPC++, all communication operations are syntactically explicit, which encourages programmers to consider the costs associated with communication and data movement. Moreover, all communication operations are asynchronous by default, encouraging programmers to seek opportunities for overlapping communication latencies with other useful work. UPC++ provides expressive and composable abstractions designed for efficiently managing aggressive use of asynchrony in programs. Together, these design principles are intended to enable programmers to write applications using UPC++ that perform well even on hundreds of thousands of cores.
Johnny Corbino, UPC++’s Crucial Role in Quantum Chemistry, UPC++ Community BOF Virtual Symposium, February 16, 2023, doi: 10.25344/S4XG6F
Paul H. Hargrove, Dan Bonachea, Johnny Corbino, Amir Kamil, Colin A. MacLean, Damian Rouson, Daniel Waters, "UPC++ and GASNet: PGAS Support for Exascale Apps and Runtimes (ECP'23)", Poster at Exascale Computing Project (ECP) Annual Meeting 2023, January 2023,
The Pagoda project is developing a programming system to support HPC application development using the Partitioned Global Address Space (PGAS) model. The first component is GASNet-EX, a portable, high-performance, global-address-space communication library. The second component is UPC++, a C++ template library. Together, these libraries enable agile, lightweight communication such as arises in irregular applications, libraries and frameworks running on exascale systems.
GASNet-EX is a portable, high-performance communications middleware library which leverages hardware support to implement Remote Memory Access (RMA) and Active Message communication primitives. GASNet-EX supports a broad ecosystem of alternative HPC programming models, including UPC++, Legion, Chapel and multiple implementations of UPC and Fortran Coarrays. GASNet-EX is implemented directly over the native APIs for networks of interest in HPC. The tight semantic match of GASNet-EX APIs to the client requirements and hardware capabilities often yields better performance than competing libraries.
UPC++ provides high-level productivity abstractions appropriate for Partitioned Global Address Space (PGAS) programming such as: remote memory access (RMA), remote procedure call (RPC), support for accelerators (e.g. GPUs), and mechanisms for aggressive asynchrony to hide communication costs. UPC++ implements communication using GASNet-EX, delivering high performance and portability from laptops to exascale supercomputers. HPC application software using UPC++ includes: MetaHipMer2 metagenome assembler, SIMCoV viral propagation simulation, NWChemEx TAMM, and graph computation kernels from ExaGraph.
2022
"Berkeley Lab’s Networking Middleware GASNet Turns 20: Now, GASNet-EX is Gearing Up for the Exascale Era", Linda Vu, HPCWire (Lawrence Berkeley National Laboratory CS Area Communications), December 7, 2022, doi: 10.25344/S4BP4G
GASNet Celebrates 20th Anniversary
For 20 years, Berkeley Lab’s GASNet has been fueling developers’ ability to tap the power of massively parallel supercomputers more effectively. The middleware was recently upgraded to support exascale scientific applications.
Katherine Rasmussen, Damian Rouson, Naje George, Dan Bonachea, Hussain Kadhem, Brian Friesen, "Agile Acceleration of LLVM Flang Support for Fortran 2018 Parallel Programming", Research Poster at the International Conference for High Performance Computing, Networking, Storage, and Analysis (SC22), November 2022, doi: 10.25344/S4CP4S
The LLVM Flang compiler ("Flang") is currently Fortran 95 compliant, and the frontend can parse Fortran 2018. However, Flang does not have a comprehensive 2018 test suite and does not fully implement the static semantics of the 2018 standard. We are investigating whether agile software development techniques, such as pair programming and test-driven development (TDD), can help Flang to rapidly progress to Fortran 2018 compliance. Because of the paramount importance of parallelism in high-performance computing, we are focusing on Fortran’s parallel features, commonly denoted “Coarray Fortran.” We are developing what we believe are the first exhaustive, open-source tests for the static semantics of Fortran 2018 parallel features, and contributing them to the LLVM project. A related effort involves writing runtime tests for parallel 2018 features and supporting those tests by developing a new parallel runtime library: the CoArray Fortran Framework of Efficient Interfaces to Network Environments (Caffeine).
Paul H. Hargrove, Dan Bonachea, "GASNet-EX RMA Communication Performance on Recent Supercomputing Systems", 5th Annual Parallel Applications Workshop, Alternatives To MPI+X (PAW-ATM'22), November 2022, doi: 10.25344/S40C7D
Partitioned Global Address Space (PGAS) programming models, typified by systems such as Unified Parallel C (UPC) and Fortran coarrays, expose one-sided Remote Memory Access (RMA) communication as a key building block for High Performance Computing (HPC) applications. Architectural trends in supercomputing make such programming models increasingly attractive, and newer, more sophisticated models such as UPC++, Legion and Chapel that rely upon similar communication paradigms are gaining popularity.
GASNet-EX is a portable, open-source, high-performance communication library designed to efficiently support the networking requirements of PGAS runtime systems and other alternative models in emerging exascale machines. The library is an evolution of the popular GASNet communication system, building upon 20 years of lessons learned. We present microbenchmark results which demonstrate the RMA performance of GASNet-EX is competitive with MPI implementations on four recent, high-impact, production HPC systems. These results are an update relative to previously published results on older systems. The networks measured here are representative of hardware currently used in six of the top ten fastest supercomputers in the world, and all of the exascale systems on the U.S. DOE road map.
Damian Rouson, Dan Bonachea, "Caffeine: CoArray Fortran Framework of Efficient Interfaces to Network Environments", Proceedings of the Eighth Annual Workshop on the LLVM Compiler Infrastructure in HPC (LLVM-HPC2022), Dallas, Texas, USA, IEEE, November 2022, doi: 10.25344/S4459B
This paper provides an introduction to the CoArray Fortran Framework of Efficient Interfaces to Network Environments (Caffeine), a parallel runtime library built atop the GASNet-EX exascale networking library. Caffeine leverages several non-parallel Fortran features to write type- and rank-agnostic interfaces and corresponding procedure definitions that support parallel Fortran 2018 features, including communication, collective operations, and related services. One major goal is to develop a runtime library that can eventually be considered for adoption by LLVM Flang, enabling that compiler to support the parallel features of Fortran. The paper describes the motivations behind Caffeine's design and implementation decisions, details the current state of Caffeine's development, and previews future work. We explain how the design and implementation offer benefits related to software sustainability by lowering the barrier to user contributions, reducing complexity through the use of Fortran 2018 C-interoperability features, and high performance through the use of a lightweight communication substrate.
Dan Bonachea, Amir Kamil, "UPC++ v1.0 Specification, Revision 2022.9.0", Lawrence Berkeley National Laboratory Tech Report, September 30, 2022, LBNL 2001480, doi: 10.25344/S4M59P
UPC++ is a C++ library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. The key communication facilities in UPC++ are one-sided Remote Memory Access (RMA) and Remote Procedure Call (RPC). All communication operations are syntactically explicit and default to non-blocking; asynchrony is managed through the use of futures, promises and continuation callbacks, enabling the programmer to construct a graph of operations to execute asynchronously as high-latency dependencies are satisfied. A global pointer abstraction provides system-wide addressability of shared memory, including host and accelerator memories. The parallelism model is primarily process-based, but the interface is thread-safe and designed to allow efficient and expressive use in multi-threaded applications. The interface is designed for extreme scalability throughout, and deliberately avoids design features that could inhibit scalability.
John Bachan, Scott B. Baden, Dan Bonachea, Johnny Corbino, Max Grossman, Paul H. Hargrove, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, Daniel Waters, "UPC++ v1.0 Programmer’s Guide, Revision 2022.9.0", Lawrence Berkeley National Laboratory Tech Report, September 30, 2022, LBNL 2001479, doi: 10.25344/S4QW26
UPC++ is a C++ library that supports Partitioned Global Address Space (PGAS) programming. It is designed for writing efficient, scalable parallel programs on distributed-memory parallel computers. The key communication facilities in UPC++ are one-sided Remote Memory Access (RMA) and Remote Procedure Call (RPC). The UPC++ control model is single program, multiple-data (SPMD), with each separate constituent process having access to local memory as it would in C++. The PGAS memory model additionally provides one-sided RMA communication to a global address space, which is allocated in shared segments that are distributed over the processes. UPC++ also features Remote Procedure Call (RPC) communication, making it easy to move computation to operate on data that resides on remote processes.
UPC++ was designed to support exascale high-performance computing, and the library interfaces and implementation are focused on maximizing scalability. In UPC++, all communication operations are syntactically explicit, which encourages programmers to consider the costs associated with communication and data movement. Moreover, all communication operations are asynchronous by default, encouraging programmers to seek opportunities for overlapping communication latencies with other useful work. UPC++ provides expressive and composable abstractions designed for efficiently managing aggressive use of asynchrony in programs. Together, these design principles are intended to enable programmers to write applications using UPC++ that perform well even on hundreds of thousands of cores.
Dan Bonachea, Paul H. Hargrove, An Introduction to GASNet-EX for Chapel Users, 9th Annual Chapel Implementers and Users Workshop (CHIUW 2022), June 10, 2022,
Have you ever typed "export CHPL_COMM=gasnet"? If you’ve used Chapel with multi-locale support on a system without "Cray" in the model name, then you’ve probably used GASNet. Did you ever wonder what GASNet is? What GASNet should mean to you? This talk aims to answer those questions and more. Chapel has system-specific implementations of multi-locale communication for Cray-branded systems including the Cray XC and HPE Cray EX lines. On other systems, Chapel communication uses the GASNet communication library embedded in third-party/gasnet. In this talk, that third-party will introduce itself to you in the first person.
Paul H. Hargrove, Dan Bonachea, Amir Kamil, Colin A. MacLean, Damian Rouson, Daniel Waters, "UPC++ and GASNet: PGAS Support for Exascale Apps and Runtimes (ECP'22)", Poster at Exascale Computing Project (ECP) Annual Meeting 2022, May 5, 2022,
We present UPC++ and GASNet-EX, distributed libraries which together enable one-sided, lightweight communication such as arises in irregular applications, libraries and frameworks running on exascale systems.
UPC++ is a C++ PGAS library, featuring APIs for Remote Procedure Call (RPC) and for Remote Memory Access (RMA) to host and GPU memories. The combination of these two features yields performant, scalable solutions to problems of interest within ECP.
GASNet-EX is PGAS communication middleware, providing the foundation for UPC++ and Legion, plus numerous non-ECP clients. GASNet-EX RMA interfaces match or exceed the performance of MPI-RMA across a variety of pre-exascale systems.
John Bachan, Scott B. Baden, Dan Bonachea, Max Grossman, Paul H. Hargrove, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, Daniel Waters, "UPC++ v1.0 Programmer’s Guide, Revision 2022.3.0", Lawrence Berkeley National Laboratory Tech Report, March 2022, LBNL 2001453, doi: 10.25344/S41C7Q
UPC++ is a C++ library that supports Partitioned Global Address Space (PGAS) programming. It is designed for writing efficient, scalable parallel programs on distributed-memory parallel computers. The key communication facilities in UPC++ are one-sided Remote Memory Access (RMA) and Remote Procedure Call (RPC). The UPC++ control model is single program, multiple-data (SPMD), with each separate constituent process having access to local memory as it would in C++. The PGAS memory model additionally provides one-sided RMA communication to a global address space, which is allocated in shared segments that are distributed over the processes. UPC++ also features Remote Procedure Call (RPC) communication, making it easy to move computation to operate on data that resides on remote processes.
UPC++ was designed to support exascale high-performance computing, and the library interfaces and implementation are focused on maximizing scalability. In UPC++, all communication operations are syntactically explicit, which encourages programmers to consider the costs associated with communication and data movement. Moreover, all communication operations are asynchronous by default, encouraging programmers to seek opportunities for overlapping communication latencies with other useful work. UPC++ provides expressive and composable abstractions designed for efficiently managing aggressive use of asynchrony in programs. Together, these design principles are intended to enable programmers to write applications using UPC++ that perform well even on hundreds of thousands of cores.
Dan Bonachea, Amir Kamil, "UPC++ v1.0 Specification, Revision 2022.3.0", Lawrence Berkeley National Laboratory Tech Report, March 2022, LBNL 2001452, doi: 10.25344/S4530J
UPC++ is a C++ library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. The key communication facilities in UPC++ are one-sided Remote Memory Access (RMA) and Remote Procedure Call (RPC). All communication operations are syntactically explicit and default to non-blocking; asynchrony is managed through the use of futures, promises and continuation callbacks, enabling the programmer to construct a graph of operations to execute asynchronously as high-latency dependencies are satisfied. A global pointer abstraction provides system-wide addressability of shared memory, including host and accelerator memories. The parallelism model is primarily process-based, but the interface is thread-safe and designed to allow efficient and expressive use in multi-threaded applications. The interface is designed for extreme scalability throughout, and deliberately avoids design features that could inhibit scalability.
2021
Daniel Waters, Colin A. MacLean, Dan Bonachea, Paul H. Hargrove, "Demonstrating UPC++/Kokkos Interoperability in a Heat Conduction Simulation (Extended Abstract)", Parallel Applications Workshop, Alternatives To MPI+X (PAW-ATM), November 2021, doi: 10.25344/S4630V
We describe the replacement of MPI with UPC++ in an existing Kokkos code that simulates heat conduction within a rectangular 3D object, as well as an analysis of the new code’s performance on CUDA accelerators. The key challenges were packing the halos in Kokkos data structures in a way that allowed for UPC++ remote memory access, and streamlining synchronization costs. Additional UPC++ abstractions used included global pointers, distributed objects, remote procedure calls, and futures. We also make use of the device allocator concept to facilitate data management in memory with unique properties, such as GPUs. Our results demonstrate that despite the algorithm’s good semantic match to message passing abstractions, straightforward modifications to use UPC++ communication deliver vastly improved performance and scalability in the common case. We find the one-sided UPC++ version written in a natural way exhibits good performance, whereas the message-passing version written in a straightforward way exhibits performance anomalies. We argue this represents a productivity benefit for one-sided communication models.
Amir Kamil, Dan Bonachea, "Optimization of Asynchronous Communication Operations through Eager Notifications", Parallel Applications Workshop, Alternatives To MPI+X (PAW-ATM), November 2021, doi: 10.25344/S42C71
UPC++ is a C++ library implementing the Asynchronous Partitioned Global Address Space (APGAS) model. We propose an enhancement to the completion mechanisms of UPC++ used to synchronize communication operations that is designed to reduce overhead for on-node operations. Our enhancement permits eager delivery of completion notification in cases where the data transfer semantics of an operation happen to complete synchronously, for example due to the use of shared-memory bypass. This semantic relaxation allows removing significant overhead from the critical path of the implementation in such cases. We evaluate our results on three different representative systems using a combination of microbenchmarks and five variations of the the HPCChallenge RandomAccess benchmark implemented in UPC++ and run on a single node to accentuate the impact of locality. We find that in RMA versions of the benchmark written in a straightforward manner (without manually optimizing for locality), the new eager notification mode can provide up to a 25% speedup when synchronizing with promises and up to a 13.5x speedup when synchronizing with conjoined futures. We also evaluate our results using a graph matching application written with UPC++ RMA communication, where we measure overall speedups of as much as 11% in single-node runs of the unmodified application code, due to our transparent enhancements.
Paul H. Hargrove, Dan Bonachea, Colin A. MacLean, Daniel Waters, "GASNet-EX Memory Kinds: Support for Device Memory in PGAS Programming Models", The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC'21) Research Poster, November 2021, doi: 10.25344/S4P306
Lawrence Berkeley National Lab is developing a programming system to support HPC application development using the Partitioned Global Address Space (PGAS) model. This work includes two major components: UPC++ (a C++ template library) and GASNet-EX (a portable, high-performance communication library). This poster describes recent advances in GASNet-EX to efficiently implement Remote Memory Access (RMA) operations to and from memory on accelerator devices such as GPUs. Performance is illustrated via benchmark results from UPC++ and the Legion programming system, both using GASNet-EX as their communications library.
Katherine A. Yelick, Amir Kamil, Damian Rouson, Dan Bonachea, Paul H. Hargrove, UPC++: An Asynchronous RMA/RPC Library for Distributed C++ Applications (SC21), Tutorial at the International Conference for High Performance Computing, Networking, Storage, and Analysis (SC21), November 15, 2021,
UPC++ is a C++ library supporting Partitioned Global Address Space (PGAS) programming. UPC++ offers low-overhead one-sided Remote Memory Access (RMA) and Remote Procedure Calls (RPC), along with future/promise-based asynchrony to express dependencies between computation and asynchronous data movement. UPC++ supports simple/regular data structures as well as more elaborate distributed applications where communication is fine-grained and/or irregular. UPC++ provides a uniform abstraction for one-sided RMA between host and GPU/accelerator memories anywhere in the system. UPC++'s support for aggressive asynchrony enables applications to effectively overlap communication and reduce latency stalls, while the underlying GASNet-EX communication library delivers efficient low-overhead RMA/RPC on HPC networks.
This tutorial introduces UPC++, covering the memory and execution models and basic algorithm implementations. Participants gain hands-on experience incorporating UPC++ features into application proxy examples. We examine a few UPC++ applications with irregular communication (metagenomic assembler and COVID-19 simulation) and describe how they utilize UPC++ to optimize communication performance.
John Bachan, Scott B. Baden, Dan Bonachea, Max Grossman, Paul H. Hargrove, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, Daniel Waters, "UPC++ v1.0 Programmer’s Guide, Revision 2021.9.0", Lawrence Berkeley National Laboratory Tech Report, September 2021, LBNL 2001424, doi: 10.25344/S4SW2T
UPC++ is a C++ library that supports Partitioned Global Address Space (PGAS) programming. It is designed for writing efficient, scalable parallel programs on distributed-memory parallel computers. The key communication facilities in UPC++ are one-sided Remote Memory Access (RMA) and Remote Procedure Call (RPC). The UPC++ control model is single program, multiple-data (SPMD), with each separate constituent process having access to local memory as it would in C++. The PGAS memory model additionally provides one-sided RMA communication to a global address space, which is allocated in shared segments that are distributed over the processes. UPC++ also features Remote Procedure Call (RPC) communication, making it easy to move computation to operate on data that resides on remote processes.
UPC++ was designed to support exascale high-performance computing, and the library interfaces and implementation are focused on maximizing scalability. In UPC++, all communication operations are syntactically explicit, which encourages programmers to consider the costs associated with communication and data movement. Moreover, all communication operations are asynchronous by default, encouraging programmers to seek opportunities for overlapping communication latencies with other useful work. UPC++ provides expressive and composable abstractions designed for efficiently managing aggressive use of asynchrony in programs. Together, these design principles are intended to enable programmers to write applications using UPC++ that perform well even on hundreds of thousands of cores.
Dan Bonachea, Amir Kamil, "UPC++ v1.0 Specification, Revision 2021.9.0", Lawrence Berkeley National Laboratory Tech Report, September 2021, LBNL 2001425, doi: 10.25344/S4XK53
UPC++ is a C++ library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. The key communication facilities in UPC++ are one-sided Remote Memory Access (RMA) and Remote Procedure Call (RPC). All communication operations are syntactically explicit and default to non-blocking; asynchrony is managed through the use of futures, promises and continuation callbacks, enabling the programmer to construct a graph of operations to execute asynchronously as high-latency dependencies are satisfied. A global pointer abstraction provides system-wide addressability of shared memory, including host and accelerator memories. The parallelism model is primarily process-based, but the interface is thread-safe and designed to allow efficient and expressive use in multi-threaded applications. The interface is designed for extreme scalability throughout, and deliberately avoids design features that could inhibit scalability.
Paul H. Hargrove, Dan Bonachea, Max Grossman, Amir Kamil, Colin A. MacLean, Daniel Waters, "UPC++ and GASNet: PGAS Support for Exascale Apps and Runtimes (ECP'21)", Poster at Exascale Computing Project (ECP) Annual Meeting 2021, April 2021,
We present UPC++ and GASNet-EX, which together enable one-sided, lightweight communication such as arises in irregular applications, libraries and frameworks running on exascale systems.
UPC++ is a C++ PGAS library, featuring APIs for Remote Memory Access (RMA) and Remote Procedure Call (RPC). The combination of these two features yields performant, scalable solutions to problems of interest within ECP.
GASNet-EX is PGAS communication middleware, providing the foundation for UPC++ and Legion, plus numerous non-ECP clients. GASNet-EX RMA interfaces match or exceed the performance of MPI-RMA across a variety of pre-exascale systems
Dan Bonachea, Amir Kamil, "UPC++ v1.0 Specification, Revision 2021.3.0", Lawrence Berkeley National Laboratory Tech Report, March 31, 2021, LBNL 2001388, doi: 10.25344/S4K881
UPC++ is a C++11 library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. The key communication facilities in UPC++ are one-sided Remote Memory Access (RMA) and Remote Procedure Call (RPC). All communication operations are syntactically explicit and default to non-blocking; asynchrony is managed through the use of futures, promises and continuation callbacks, enabling the programmer to construct a graph of operations to execute asynchronously as high-latency dependencies are satisfied. A global pointer abstraction provides system-wide addressability of shared memory, including host and accelerator memories. The parallelism model is primarily process-based, but the interface is thread-safe and designed to allow efficient and expressive use in multi-threaded applications. The interface is designed for extreme scalability throughout, and deliberately avoids design features that could inhibit scalability.
Dan Bonachea, GASNet-EX: A High-Performance, Portable Communication Library for Exascale, Berkeley Lab – CS Seminar, March 10, 2021,
- Download File: GASNet-2021-LBL-seminar-slides.pdf (pdf: 9.1 MB)
Partitioned Global Address Space (PGAS) models, pioneered by languages such as Unified Parallel C (UPC) and Co-Array Fortran, expose one-sided communication as a key building block for High Performance Computing (HPC) applications. Architectural trends in supercomputing make such programming models increasingly attractive, and newer, more sophisticated models such as UPC++, Legion and Chapel that rely upon similar communication paradigms are gaining popularity.
GASNet-EX is a portable, open-source, high-performance communication library designed to efficiently support the networking requirements of PGAS runtime systems and other alternative models in future exascale machines. The library is an evolution of the popular GASNet communication system, building on 20 years of lessons learned. We describe several features and enhancements that have been introduced to address the needs of modern runtimes and exploit the hardware capabilities of emerging systems. Microbenchmark results demonstrate the RMA performance of GASNet-EX is competitive with several MPI implementations on current systems. GASNet-EX provides communication services that help to deliver speedups in HPC applications written using the UPC++ library, enabling new science on pre-exascale systems.
2020
Katherine A. Yelick, Amir Kamil, Dan Bonachea, Paul H Hargrove, UPC++: An Asynchronous RMA/RPC Library for Distributed C++ Applications (SC20), Tutorial at the International Conference for High Performance Computing, Networking, Storage, and Analysis (SC20), November 10, 2020,
This tutorial introduces basic concepts and advanced optimization techniques of UPC++. We discuss the UPC++ memory and execution models and examine basic algorithm implementations. Participants gain hands-on experience incorporating UPC++ features into several application examples. We also examine two irregular applications (metagenomic assembler and multifrontal sparse solver) and describe how they leverage UPC++ features to optimize communication performance.
John Bachan, Scott B. Baden, Dan Bonachea, Max Grossman, Paul H. Hargrove, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, "UPC++ v1.0 Programmer’s Guide, Revision 2020.10.0", Lawrence Berkeley National Laboratory Tech Report, October 2020, LBNL 2001368, doi: 10.25344/S4HG6Q
UPC++ is a C++11 library that provides Partitioned Global Address Space (PGAS) programming. It is designed for writing parallel programs that run efficiently and scale well on distributed-memory parallel computers. The PGAS model is single program, multiple-data (SPMD), with each separate constituent process having access to local memory as it would in C++. However, PGAS also provides access to a global address space, which is allocated in shared segments that are distributed over the processes. UPC++ provides numerous methods for accessing and using global memory. In UPC++, all operations that access remote memory are explicit, which encourages programmers to be aware of the cost of communication and data movement. Moreover, all remote-memory access operations are by default asynchronous, to enable programmers to write code that scales well even on hundreds of thousands of cores.
Dan Bonachea, Amir Kamil, "UPC++ v1.0 Specification, Revision 2020.10.0", Lawrence Berkeley National Laboratory Tech Report, October 30, 2020, LBNL 2001367, doi: 10.25344/S4CS3F
UPC++ is a C++11 library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. The key communication facilities in UPC++ are one-sided Remote Memory Access (RMA) and Remote Procedure Call (RPC). All communication operations are syntactically explicit and default to non-blocking; asynchrony is managed through the use of futures, promises and continuation callbacks, enabling the programmer to construct a graph of operations to execute asynchronously as high-latency dependencies are satisfied. A global pointer abstraction provides system-wide addressability of shared memory, including host and accelerator memories. The parallelism model is primarily process-based, but the interface is thread-safe and designed to allow efficient and expressive use in multi-threaded applications. The interface is designed for extreme scalability throughout, and deliberately avoids design features that could inhibit scalability.
Steven Hofmeyr, Rob Egan, Evangelos Georganas, Alex C Copeland, Robert Riley, Alicia Clum, Emiley Eloe-Fadrosh, Simon Roux, Eugene Goltsman, Aydin Buluc, Daniel Rokhsar, Leonid Oliker, Katherine Yelick, "Terabase-scale metagenome coassembly with MetaHipMer", Scientific Reports, June 1, 2020, 10, doi: https://doi.org/10.1038/s41598-020-67416-5
- Download File: s41598-020-67416-5.pdf (pdf: 1.4 MB)
Metagenome sequence datasets can contain terabytes of reads, too many to be coassembled together on a single shared-memory computer; consequently, they have only been assembled sample by sample (multiassembly) and combining the results is challenging. We can now perform coassembly of the largest datasets using MetaHipMer, a metagenome assembler designed to run on supercomputers and large clusters of compute nodes. We have reported on the implementation of MetaHipMer previously; in this paper we focus on analyzing the impact of very large coassembly. In particular, we show that coassembly recovers a larger genome fraction than multiassembly and enables the discovery of more complete genomes, with lower error rates, whereas multiassembly recovers more dominant strain variation. Being able to coassemble a large dataset does not preclude one from multiassembly; rather, having a fast, scalable metagenome assembler enables a user to more easily perform coassembly and multiassembly, and assemble both abundant, high strain variation genomes, and low-abundance, rare genomes. We present several assemblies of terabyte datasets that could never be coassembled before, demonstrating MetaHipMer’s scaling power. MetaHipMer is available for public use under an open source license and all datasets used in the paper are available for public download.
Amir Kamil, John Bachan, Scott B. Baden, Dan Bonachea, Rob Egan, Paul Hargrove, Steven Hofmeyr, Mathias Jacquelin, Kathy Yelick, UPC++: An Asynchronous RMA/RPC Library for Distributed C++ Applications (ALCF'20), Argonne Leadership Computing Facility (ALCF) Webinar Series, May 27, 2020,
UPC++ is a C++ library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. The UPC++ API offers low-overhead one-sided RMA communication and Remote Procedure Calls (RPC), along with futures and promises. These constructs enable the programmer to express dependencies between asynchronous computations and data movement. UPC++ supports the implementation of simple, regular data structures as well as more elaborate distributed data structures where communication is fine-grained, irregular, or both. The library’s support for asynchrony enables the application to aggressively overlap and schedule communication and computation to reduce wait times.
UPC++ is highly portable and runs on platforms from laptops to supercomputers, with native implementations for HPC interconnects. As a C++ library, it interoperates smoothly with existing numerical libraries and on-node programming models (e.g., OpenMP, CUDA).
In this webinar, hosted by DOE’s Exascale Computing Project and the ALCF, we will introduce basic concepts and advanced optimization techniques of UPC++. We will discuss the UPC++ memory and execution models and walk through basic algorithm implementations. We will also look at irregular applications and show how they can take advantage of UPC++ features to optimize their performance.
John Bachan, Scott B. Baden, Dan Bonachea, Max Grossman, Paul H. Hargrove, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, "UPC++ v1.0 Programmer’s Guide, Revision 2020.3.0", Lawrence Berkeley National Laboratory Tech Report, March 2020, LBNL 2001269, doi: 10.25344/S4P88Z
UPC++ is a C++11 library that provides Partitioned Global Address Space (PGAS) programming. It is designed for writing parallel programs that run efficiently and scale well on distributed-memory parallel computers. The PGAS model is single program, multiple-data (SPMD), with each separate constituent process having access to local memory as it would in C++. However, PGAS also provides access to a global address space, which is allocated in shared segments that are distributed over the processes. UPC++ provides numerous methods for accessing and using global memory. In UPC++, all operations that access remote memory are explicit, which encourages programmers to be aware of the cost of communication and data movement. Moreover, all remote-memory access operations are by default asynchronous, to enable programmers to write code that scales well even on hundreds of thousands of cores.
John Bachan, Dan Bonachea, Amir Kamil, "UPC++ v1.0 Specification, Revision 2020.3.0", Lawrence Berkeley National Laboratory Tech Report, March 12, 2020, LBNL 2001268, doi: 10.25344/S4T01S
UPC++ is a C++11 library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. The key communication facilities in UPC++ are one-sided Remote Memory Access (RMA) and Remote Procedure Call (RPC). All communication operations are syntactically explicit and default to non-blocking; asynchrony is managed through the use of futures, promises and continuation callbacks, enabling the programmer to construct a graph of operations to execute asynchronously as high-latency dependencies are satisfied. A global pointer abstraction provides system-wide addressability of shared memory, including host and accelerator memories. The parallelism model is primarily process-based, but the interface is thread-safe and designed to allow efficient and expressive use in multi-threaded applications. The interface is designed for extreme scalability throughout, and deliberately avoids design features that could inhibit scalability.
Amir Kamil, John Bachan, Scott B. Baden, Dan Bonachea, Rob Egan, Paul Hargrove, Steven Hofmeyr, Mathias Jacquelin, Kathy Yelick, UPC++: A PGAS/RPC Library for Asynchronous Exascale Communication in C++ (ECP'20), Tutorial at Exascale Computing Project (ECP) Annual Meeting 2020, February 6, 2020,
UPC++ is a C++ library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. The UPC++ API offers low-overhead one-sided RMA communication and Remote Procedure Calls (RPC), along with futures and promises. These constructs enable the programmer to express dependencies between asynchronous computations and data movement. UPC++ supports the implementation of simple, regular data structures as well as more elaborate distributed data structures where communication is fine-grained, irregular, or both. The library’s support for asynchrony enables the application to aggressively overlap and schedule communication and computation to reduce wait times.
UPC++ is highly portable and runs on platforms from laptops to supercomputers, with native implementations for HPC interconnects. As a C++ library, it interoperates smoothly with existing numerical libraries and on-node programming models (e.g., OpenMP, CUDA).
In this tutorial we will introduce basic concepts and advanced optimization techniques of UPC++. We will discuss the UPC++ memory and execution models and walk through basic algorithm implementations. We will also look at irregular applications and show how they can take advantage of UPC++ features to optimize their performance.
Amir Kamil, John Bachan, Dan Bonachea, Paul H. Hargrove, Erich Strohmaier and Daniel Waters, "UPC++: Asynchronous RMA and RPC Communication for Exascale Applications (ECP'20)", Poster at Exascale Computing Project (ECP) Annual Meeting 2020, February 2020,
Paul H. Hargrove, Dan Bonachea, "GASNet-EX: RMA and Active Message Communication for Exascale Programming Models (ECP'20)", Poster at Exascale Computing Project (ECP) Annual Meeting 2020, February 2020,
2019
Amir Kamil, John Bachan, Scott B. Baden, Dan Bonachea, Paul Hargrove, Steven Hofmeyr, Kathy Yelick, UPC++ Tutorial (NERSC Dec 2019), National Energy Research Scientific Computing Center (NERSC), December 16, 2019,
This event was a repeat of the tutorial delivered on November 1, but with the restoration of the hands-on component which was omitted due to uncertainty surrounding the power outage at NERSC.
UPC++ is a C++11 library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. UPC++ provides mechanisms for low-overhead one-sided communication, moving computation to data through remote-procedure calls, and expressing dependencies between asynchronous computations and data movement. It is particularly well-suited for implementing elaborate distributed data structures where communication is irregular or fine-grained. The UPC++ interfaces are designed to be composable and similar to those used in conventional C++. The UPC++ programmer can expect communication to run at close to hardware speeds.
In this tutorial we introduced basic concepts and advanced optimization techniques of UPC++. We discussed the UPC++ memory and execution models and walked through implementing basic algorithms in UPC++. We also discussed irregular applications and how to take advantage of UPC++ features to optimize their performance. The tutorial included hands-on exercises with basic UPC++ constructs. Registrants were given access to run their UPC++ exercises on NERSC’s Cori (currently the #14 fastest computer in the world).

Paul H. Hargrove, Dan Bonachea, "Efficient Active Message RMA in GASNet Using a Target-Side Reassembly Protocol (Extended Abstract)", IEEE/ACM Parallel Applications Workshop, Alternatives To MPI+X (PAW-ATM), Lawrence Berkeley National Laboratory Technical Report, November 17, 2019, LBNL 2001238, doi: 10.25344/S4PC7M
Alexander Pöppl, Scott Baden, Michael Bader, "A UPC++ Actor Library and Its Evaluation On a Shallow Water Proxy Application", 2019 IEEE/ACM Parallel Applications Workshop, Alternatives To MPI (PAW-ATM), ACM, November 17, 2019, doi: 10.1109/PAW-ATM49560.2019.00007
Programmability is one of the key challenges of Exascale Computing. Using the actor model for distributed computations may be one solution. The actor model separates computation from communication while still enabling their overlap. Each actor possesses specified communication endpoints to publish and receive information. Computations are undertaken based on the data available on these channels. We present a library that implements this programming model using UPC++, a PGAS library, and evaluate three different parallelization strategies, one based on rank-sequential execution, one based on multiple threads in a rank, and one based on OpenMP tasks. In an evaluation of our library using shallow water proxy applications, our solution compares favorably against an earlier implementation based on X10, and a BSP-based approach.
Dan Bonachea, Paul H. Hargrove, "GASNet-EX: A High-Performance, Portable Communication Library for Exascale", LNCS 11882: Proceedings of Languages and Compilers for Parallel Computing (LCPC'18), edited by Hall M., Sundar H., November 2019, 11882:138-158, doi: 10.1007/978-3-030-34627-0_11
- Download File: gasnet-ex-lcpc18-8c39995-final.pdf (pdf: 520 KB)
Partitioned Global Address Space (PGAS) models, typified by such languages as Unified Parallel C (UPC) and Co-Array Fortran, expose one-sided communication as a key building block for High Performance Computing (HPC) applications. Architectural trends in supercomputing make such programming models increasingly attractive, and newer, more sophisticated models such as UPC++, Legion and Chapel that rely upon similar communication paradigms are gaining popularity.
GASNet-EX is a portable, open-source, high-performance communication library designed to efficiently support the networking requirements of PGAS runtime systems and other alternative models in future exascale machines. The library is an evolution of the popular GASNet communication system, building upon over 15 years of lessons learned. We describe and evaluate several features and enhancements that have been introduced to address the needs of modern client systems. Microbenchmark results demonstrate the RMA performance of GASNet-EX is competitive with several MPI-3 implementations on current HPC systems.
Amir Kamil, John Bachan, Scott B. Baden, Dan Bonachea, Rob Egan, Paul Hargrove, Steven Hofmeyr, Mathias Jacquelin, Kathy Yelick, UPC++ Tutorial (NERSC Nov 2019), National Energy Research Scientific Computing Center (NERSC), November 1, 2019,
UPC++ is a C++11 library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. UPC++ provides mechanisms for low-overhead one-sided communication, moving computation to data through remote-procedure calls, and expressing dependencies between asynchronous computations and data movement. It is particularly well-suited for implementing elaborate distributed data structures where communication is irregular or fine-grained. The UPC++ interfaces are designed to be composable and similar to those used in conventional C++. The UPC++ programmer can expect communication to run at close to hardware speeds.
In this tutorial we will introduce basic concepts and advanced optimization techniques of UPC++. We will discuss the UPC++ memory and execution models and walk through implementing basic algorithms in UPC++. We will also look at irregular applications and how to take advantage of UPC++ features to optimize their performance.
John Bachan, Scott Baden, Dan Bonachea, Paul Hargrove, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, "UPC++ v1.0 Programmer’s Guide, Revision 2019.9.0", Lawrence Berkeley National Laboratory Tech Report, September 2019, LBNL 2001236, doi: 10.25344/S4V30R
UPC++ is a C++11 library that provides Partitioned Global Address Space (PGAS) programming. It is designed for writing parallel programs that run efficiently and scale well on distributed-memory parallel computers. The PGAS model is single program, multiple-data (SPMD), with each separate constituent process having access to local memory as it would in C++. However, PGAS also provides access to a global address space, which is allocated in shared segments that are distributed over the processes. UPC++ provides numerous methods for accessing and using global memory. In UPC++, all operations that access remote memory are explicit, which encourages programmers to be aware of the cost of communication and data movement. Moreover, all remote-memory access operations are by default asynchronous, to enable programmers to write code that scales well even on hundreds of thousands of cores.
John Bachan, Scott Baden, Dan Bonachea, Paul Hargrove, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, "UPC++ v1.0 Specification, Revision 2019.9.0", Lawrence Berkeley National Laboratory Tech Report, September 14, 2019, LBNL 2001237, doi: 10.25344/S4ZW2C
UPC++ is a C++11 library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. We are revising the library under the auspices of the DOE’s Exascale Computing Project, to meet the needs of applications requiring PGAS support. UPC++ is intended for implementing elaborate distributed data structures where communication is irregular or fine-grained. The UPC++ interfaces for moving non-contiguous data and handling memories with different optimal access methods are composable and similar to those used in conventional C++. The UPC++ programmer can expect communication to run at close to hardware speeds. The key facilities in UPC++ are global pointers, that enable the programmer to express ownership information for improving locality, one-sided communication, both put/get and RPC, futures and continuations. Futures capture data readiness state, which is useful in making scheduling decisions, and continuations provide for completion handling via callbacks. Together, these enable the programmer to chain together a DAG of operations to execute asynchronously as high-latency dependencies become satisfied.
John Bachan, Scott B. Baden, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Dan Bonachea, Paul H. Hargrove, Hadia Ahmed, "UPC++: A High-Performance Communication Framework for Asynchronous Computation", 33rd IEEE International Parallel & Distributed Processing Symposium (IPDPS'19), Rio de Janeiro, Brazil, IEEE, May 2019, doi: 10.25344/S4V88H
John Bachan, Scott Baden, Dan Bonachea, Paul Hargrove, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, "UPC++ Programmer's Guide, v1.0-2019.3.0", Lawrence Berkeley National Laboratory Tech Report, March 2019, LBNL 2001191, doi: 10.25344/S4F301
UPC++ is a C++11 library that provides Partitioned Global Address Space (PGAS) programming. It is designed for writing parallel programs that run efficiently and scale well on distributed-memory parallel computers. The PGAS model is single program, multiple-data (SPMD), with each separate constituent process having access to local memory as it would in C++. However, PGAS also provides access to a global address space, which is allocated in shared segments that are distributed over the processes. UPC++ provides numerous methods for accessing and using global memory. In UPC++, all operations that access remote memory are explicit, which encourages programmers to be aware of the cost of communication and data movement. Moreover, all remote-memory access operations are by default asynchronous, to enable programmers to write code that scales well even on hundreds of thousands of cores.
John Bachan, Scott Baden, Dan Bonachea, Paul Hargrove, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, "UPC++ Specification v1.0, Draft 10", Lawrence Berkeley National Laboratory Tech Report, March 15, 2019, LBNL 2001192, doi: 10.25344/S4JS30
UPC++ is a C++11 library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. We are revising the library under the auspices of the DOE’s Exascale Computing Project, to meet the needs of applications requiring PGAS support. UPC++ is intended for implementing elaborate distributed data structures where communication is irregular or fine-grained. The UPC++ interfaces for moving non-contiguous data and handling memories with different optimal access methods are composable and similar to those used in conventional C++. The UPC++ programmer can expect communication to run at close to hardware speeds. The key facilities in UPC++ are global pointers, that enable the programmer to express ownership information for improving locality, one-sided communication, both put/get and RPC, futures and continuations. Futures capture data readiness state, which is useful in making scheduling decisions, and continuations provide for completion handling via callbacks. Together, these enable the programmer to chain together a DAG of operations to execute asynchronously as high-latency dependencies become satisfied.
Scott B. Baden, Paul H. Hargrove, Hadia Ahmed, John Bachan, Dan Bonachea, Steve Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, "Pagoda: Lightweight Communications and Global Address Space Support for Exascale Applications - UPC++ (ECP'19)", Poster at Exascale Computing Project (ECP) Annual Meeting 2019, January 2019,
Scott B. Baden, Paul H. Hargrove, Dan Bonachea, "Pagoda: Lightweight Communications and Global Address Space Support for Exascale Applications - GASNet-EX (ECP'19)", Poster at Exascale Computing Project (ECP) Annual Meeting 2019, January 2019,
2018
Paul H. Hargrove, Dan Bonachea, "GASNet-EX Performance Improvements Due to Specialization for the Cray Aries Network", Parallel Applications Workshop, Alternatives To MPI (PAW-ATM), Dallas, Texas, USA, IEEE, November 16, 2018, 23-33, doi: 10.25344/S44S38
GASNet-EX is a portable, open-source, high-performance communication library designed to efficiently support the networking requirements of PGAS runtime systems and other alternative models on future exascale machines. This paper reports on the improvements in performance observed on Cray XC-series systems due to enhancements made to the GASNet-EX software. These enhancements, known as "specializations", primarily consist of replacing network-independent implementations of several recently added features with implementations tailored to the Cray Aries network. Performance gains from specialization include (1) Negotiated-Payload Active Messages improve bandwidth of a ping-pong test by up to 14%, (2) Immediate Operations reduce running time of a synthetic benchmark by up to 93%, (3) non-bulk RMA Put bandwidth is increased by up to 32%, (4) Remote Atomic performance is 70% faster than the reference on a point-to-point test and allows a hot-spot test to scale robustly, and (5) non-contiguous RMA interfaces see up to 8.6x speedups for an intra-node benchmark and 26% for inter-node. These improvements are all available in GASNet-EX version 2018.3.0 and later.
Scott B. Baden, Paul H. Hargrove, Hadia Ahmed, John Bachan, Dan Bonachea, Steve Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, "UPC++ and GASNet-EX: PGAS Support for Exascale Applications and Runtimes", The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC'18) Research Poster, November 2018,
Lawrence Berkeley National Lab is developing a programming system to support HPC application development using the Partitioned Global Address Space (PGAS) model. This work is driven by the emerging need for adaptive, lightweight communication in irregular applications at exascale. We present an overview of UPC++ and GASNet-EX, including examples and performance results.
GASNet-EX is a portable, high-performance communication library, leveraging hardware support to efficiently implement Active Messages and Remote Memory Access (RMA). UPC++ provides higher-level abstractions appropriate for PGAS programming such as: one-sided communication (RMA), remote procedure call, locality-aware APIs for user-defined distributed objects, and robust support for asynchronous execution to hide latency. Both libraries have been redesigned relative to their predecessors to meet the needs of exascale computing. While both libraries continue to evolve, the system already demonstrates improvements in microbenchmarks and application proxies.
Dan Bonachea, Paul H. Hargrove, "GASNet-EX: A High-Performance, Portable Communication Library for Exascale", Languages and Compilers for Parallel Computing (LCPC'18), Salt Lake City, Utah, USA, October 11, 2018, LBNL 2001174, doi: 10.25344/S4QP4W
Partitioned Global Address Space (PGAS) models, typified by such languages as Unified Parallel C (UPC) and Co-Array Fortran, expose one-sided communication as a key building block for High Performance Computing (HPC) applications. Architectural trends in supercomputing make such programming models increasingly attractive, and newer, more sophisticated models such as UPC++, Legion and Chapel that rely upon similar communication paradigms are gaining popularity.
GASNet-EX is a portable, open-source, high-performance communication library designed to efficiently support the networking requirements of PGAS runtime systems and other alternative models in future exascale machines. The library is an evolution of the popular GASNet communication system, building upon over 15 years of lessons learned. We describe and evaluate several features and enhancements that have been introduced to address the needs of modern client systems. Microbenchmark results demonstrate the RMA performance of GASNet-EX is competitive with several MPI-3 implementations on current HPC systems.
John Bachan, Scott Baden, Dan Bonachea, Paul Hargrove, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, "UPC++ Programmer's Guide, v1.0-2018.9.0", Lawrence Berkeley National Laboratory Tech Report, September 2018, LBNL 2001180, doi: 10.25344/S49G6V
UPC++ is a C++11 library that provides Partitioned Global Address Space (PGAS) programming. It is designed for writing parallel programs that run efficiently and scale well on distributed-memory parallel computers. The PGAS model is single program, multiple-data (SPMD), with each separate constituent process having access to local memory as it would in C++. However, PGAS also provides access to a global address space, which is allocated in shared segments that are distributed over the processes. UPC++ provides numerous methods for accessing and using global memory. In UPC++, all operations that access remote memory are explicit, which encourages programmers to be aware of the cost of communication and data movement. Moreover, all remote-memory access operations are by default asynchronous, to enable programmers to write code that scales well even on hundreds of thousands of cores.
John Bachan, Scott Baden, Dan Bonachea, Paul Hargrove, Steven Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, "UPC++ Specification v1.0, Draft 8", Lawrence Berkeley National Laboratory Tech Report, September 26, 2018, LBNL 2001179, doi: 10.25344/S45P4X
UPC++ is a C++11 library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. We are revising the library under the auspices of the DOE’s Exascale Computing Project, to meet the needs of applications requiring PGAS support. UPC++ is intended for implementing elaborate distributed data structures where communication is irregular or fine-grained. The UPC++ interfaces for moving non-contiguous data and handling memories with different optimal access methods are composable and similar to those used in conventional C++. The UPC++ programmer can expect communication to run at close to hardware speeds. The key facilities in UPC++ are global pointers, that enable the programmer to express ownership information for improving locality, one-sided communication, both put/get and RPC, futures and continuations. Futures capture data readiness state, which is useful in making scheduling decisions, and continuations provide for completion handling via callbacks. Together, these enable the programmer to chain together a DAG of operations to execute asynchronously as high-latency dependencies become satisfied.
"Pagoda: Communication Software Libraries for Exascale Computing", Mike Bernhardt, Lawrence Berkeley National Laboratory CS Area Communications, April 5, 2018,
A Berkeley Lab team leads the development of communication software libraries with low operating overheads to tap the high performance of DOE’s exascale computers.
Dan Bonachea, Paul Hargrove, "GASNet-EX Performance Improvements Due to Specialization for the Cray Aries Network (tech report version)", Lawrence Berkeley National Laboratory Tech Report, March 27, 2018, LBNL 2001134, doi: 10.2172/1430690
This document is a deliverable for milestone STPM17-6 of the Exascale Computing Project, delivered by WBS 2.3.1.14. It reports on the improvements in performance observed on Cray XC-series systems due to enhancements made to the GASNet-EX software. These enhancements, known as “specializations”, primarily consist of replacing network-independent implementations of several recently added features with implementations tailored to the Cray Aries network. Performance gains from specialization include (1) Negotiated-Payload Active Messages improve bandwidth of a ping-pong test by up to 14%, (2) Immediate Operations reduce running time of a synthetic benchmark by up to 93%, (3) non-bulk RMA Put bandwidth is increased by up to 32%, (4) Remote Atomic performance is 70% faster than the reference on a point-to-point test and allows a hot-spot test to scale robustly, and (5) non-contiguous RMA interfaces see up to 8.6x speedups for an intra-node benchmark and 26% for inter-node. These improvements are available in the GASNet-EX 2018.3.0 release.
John Bachan, Scott Baden, Dan Bonachea, Paul H. Hargrove, Steven Hofmeyr, Khaled Ibrahim, Mathias Jacquelin, Amir Kamil, Bryce Lelbach, Brian Van Straalen, "UPC++ Specification v1.0, Draft 6", Lawrence Berkeley National Laboratory Tech Report, March 26, 2018, LBNL 2001135, doi: 10.2172/1430689
UPC++ is a C++11 library providing classes and functions that support Partitioned Global Address Space (PGAS) programming. We are revising the library under the auspices of the DOE’s Exascale Computing Project, to meet the needs of applications requiring PGAS support. UPC++ is intended for implementing elaborate distributed data structures where communication is irregular or fine-grained. The UPC++ interfaces for moving non-contiguous data and handling memories with different optimal access methods are composable and similar to those used in conventional C++. The UPC++ programmer can expect communication to run at close to hardware speeds. The key facilities in UPC++ are global pointers, that enable the programmer to express ownership information for improving locality, one-sided communication, both put/get and RPC, futures and continuations. Futures capture data readiness state, which is useful in making scheduling decisions, and continuations provide for completion handling via callbacks. Together, these enable the programmer to chain together a DAG of operations to execute asynchronously as high-latency dependencies become satisfied.
John Bachan, Scott Baden, Dan Bonachea, Paul H. Hargrove, Steven Hofmeyr, Khaled Ibrahim, Mathias Jacquelin, Amir Kamil, Brian Van Straalen, "UPC++ Programmer’s Guide, v1.0-2018.3.0", Lawrence Berkeley National Laboratory Tech Report, March 2018, LBNL 2001136, doi: 10.2172/1430693
UPC++ is a C++11 library that provides Partitioned Global Address Space (PGAS) programming. It is designed for writing parallel programs that run efficiently and scale well on distributed-memory parallel computers. The PGAS model is single program, multiple-data (SPMD), with each separate thread of execution (referred to as a rank, a term borrowed from MPI) having access to local memory as it would in C++. However, PGAS also provides access to a global address space, which is allocated in shared segments that are distributed over the ranks. UPC++ provides numerous methods for accessing and using global memory. In UPC++, all operations that access remote memory are explicit, which encourages programmers to be aware of the cost of communication and data movement. Moreover, all remote-memory access operations are by default asynchronous, to enable programmers to write code that scales well even on hundreds of thousands of cores.
John Bachan, Scott Baden, Dan Bonachea, Paul Hargrove, Steven Hofmeyr, Khaled Ibrahim, Mathias Jacquelin, Amir Kamil, Brian van Straalen, "UPC++ and GASNet: PGAS Support for Exascale Apps and Runtimes (ECP'18)", Poster at Exascale Computing Project (ECP) Annual Meeting 2018, February 2018,
Scott Baden, Dan Bonachea, Paul Hargrove, "GASNet-EX: PGAS Support for Exascale Apps and Runtimes (ECP'18)", Poster at Exascale Computing Project (ECP) Annual Meeting 2018, February 2018,
2017
John Bachan, Scott Baden, Dan Bonachea, Paul Hargrove, Steven Hofmeyr, Khaled Ibrahim, Mathias Jacquelin, Amir Kamil, Brian Van Straalen, "UPC++: a PGAS C++ Library", The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC'17) Research Poster, November 2017,
John Bachan, Dan Bonachea, Paul H Hargrove, Steve Hofmeyr, Mathias Jacquelin, Amir Kamil, Brian van Straalen, Scott B Baden, "The UPC++ PGAS library for Exascale Computing", Proceedings of the Second Annual PGAS Applications Workshop (PAW17), November 13, 2017, doi: 10.1145/3144779.3169108
We describe UPC++ V1.0, a C++11 library that supports APGAS programming. UPC++ targets distributed data structures where communication is irregular or fine-grained. The key abstractions are global pointers, asynchronous programming via RPC, and futures. Global pointers incorporate ownership information useful in optimizing for locality. Futures capture data readiness state, are useful for scheduling and also enable the programmer to chain operations to execute asynchronously as high-latency dependencies become satisfied, via continuations. The interfaces for moving non-contiguous data and handling memories with different optimal access methods are composable and closely resemble those used in modern C++. Communication in UPC++ runs at close to hardware speeds by utilizing the low-overhead GASNet-EX communication library.
Erik Paulson, Dan Bonachea, Paul Hargrove, GASNet ofi-conduit, Presentation at the Open Fabrics Interface BoF at Supercomputing 2017, November 2017,
"ECP Pagoda Project Rolls Out First Software Libraries", Kathy Kincade, Lawrence Berkeley National Laboratory CS Area Communications, November 1, 2017,
Just one year after the U.S. Department of Energy's (DOE) Exascale Computing Program (ECP) began funding projects to prepare scientific applications for exascale supercomputers, the Pagoda Project—a three-year ECP software development program based at Lawrence Berkeley National Laboratory—has successfully reached a major milestone: making its open source software libraries publicly available as of September 30, 2017.
John Bachan, Scott Baden, Dan Bonachea, Paul Hargrove, Steven Hofmeyr, Khaled Ibrahim, Mathias Jacquelin, Amir Kamil, Brian van Straalen, "UPC++ Programmer’s Guide, v1.0-2017.9", Lawrence Berkeley National Laboratory Tech Report, September 2017, LBNL 2001065, doi: 10.2172/1398522
UPC++ is a C++11 library that provides Asynchronous Partitioned Global Address Space (APGAS) programming. It is designed for writing parallel programs that run efficiently and scale well on distributed-memory parallel computers. The APGAS model is single program, multiple-data (SPMD), with each separate thread of execution (referred to as a rank, a term borrowed from MPI) having access to local memory as it would in C++. However, APGAS also provides access to a global address space, which is allocated in shared segments that are distributed over the ranks. UPC++ provides numerous methods for accessing and using global memory. In UPC++, all operations that access remote memory are explicit, which encourages programmers to be aware of the cost of communication and data movement. Moreover, all remote-memory access operations are by default asynchronous, to enable programmers to write code that scales well even on hundreds of thousands of cores.
John Bachan, Scott Baden, Dan Bonachea, Paul H. Hargrove, Steven Hofmeyr, Khaled Ibrahim, Mathias Jacquelin, Amir Kamil, Bryce Lelbach, Brian Van Straalen, "UPC++ Specification v1.0, Draft 4", Lawrence Berkeley National Laboratory Tech Report, September 27, 2017, LBNL 2001066, doi: 10.2172/1398521
UPC++ is a C++11 library providing classes and functions that support Asynchronous Partitioned Global Address Space (APGAS) programming. We are revising the library under the auspices of the DOE’s Exascale Computing Project, to meet the needs of applications requiring PGAS support. UPC++ is intended for implementing elaborate distributed data structures where communication is irregular or fine-grained. The UPC++ interfaces for moving non-contiguous data and handling memories with different optimal access methods are composable and similar to those used in conventional C++. The UPC++ programmer can expect communication to run at close to hardware speeds. The key facilities in UPC++ are global pointers, that enable the programmer to express ownership information for improving locality, one-sided communication, both put/get and RPC, futures and continuations. Futures capture data readiness state, which is useful in making scheduling decisions, and continuations provide for completion handling via callbacks. Together, these enable the programmer to chain together a DAG of operations to execute asynchronously as high-latency dependencies become satisfied.
Dan Bonachea, Paul Hargrove, "GASNet Specification, v1.8.1", Lawrence Berkeley National Laboratory Tech Report, August 31, 2017, LBNL 2001064, doi: 10.2172/1398512
GASNet is a language-independent, low-level networking layer that provides network-independent, high-performance communication primitives tailored for implementing parallel global address space SPMD languages and libraries such as UPC, UPC++, Co-Array Fortran, Legion, Chapel, and many others. The interface is primarily intended as a compilation target and for use by runtime library writers (as opposed to end users), and the primary goals are high performance, interface portability, and expressiveness. GASNet stands for "Global-Address Space Networking".
John Bachan, Scott Baden, Dan Bonachea, Paul Hargrove, Steven Hofmeyr, Khaled Ibrahim, Mathias Jacquelin, Amir Kamil, Brian van Straalen, "UPC++ and GASNet: PGAS Support for Exascale Apps and Runtimes (ECP'17)", Poster at Exascale Computing Project (ECP) Annual Meeting 2017, January 2, 2017,
2016
Mathias Jacquelin, Yili Zheng, Esmond Ng, Katherine Yelick, "An Asynchronous Task-based Fan-Both Sparse Cholesky Solver", August 23, 2016,
Systems of linear equations arise at the heart of many scientific and engineering applications. Many of these linear systems are sparse; i.e., most of the elements in the coefficient matrix are zero. Direct methods based on matrix factorizations are sometimes needed to ensure accurate solutions. For example, accurate solution of sparse linear systems is needed in shift-invert Lanczos to compute interior eigenvalues. The performance and resource usage of sparse matrix factorizations are critical to time-to-solution and maximum problem size solvable on a given platform. In many applications, the coefficient matrices are symmetric, and exploiting symmetry will reduce both the amount of work and storage cost required for factorization. When the factorization is performed on large-scale distributed memory platforms, communication cost is critical to the performance of the algorithm. At the same time, network topologies have become increasingly complex, so that modern platforms exhibit a high level of performance variability. This makes scheduling of computations an intricate and performance-critical task. In this paper, we investigate the use of an asynchronous task paradigm, one-sided communication and dynamic scheduling in implementing sparse Cholesky factorization (symPACK) on large-scale distributed memory platforms. Our solver symPACK relies on efficient and flexible communication primitives provided by the UPC++ library. Performance evaluation shows good scalability and that symPACK outperforms state-of-the-art parallel distributed memory factorization packages, validating our approach on practical cases.
D Ozog, A Kamil, Y Zheng, P Hargrove, JR Hammond, A Malony, WD Jong, K Yelick, "A Hartree-Fock Application Using UPC++ and the New DArray Library", 30th International Parallel and Distributed Processing Symposium (IPDPS), IEEE, May 23, 2016, 453--462, doi: 10.1109/IPDPS.2016.108
The Hartree-Fock (HF) method is the fundamental first step for incorporating quantum mechanics into many-electron simulations of atoms and molecules, and it is an important component of computational chemistry toolkits like NWChem. The GTFock code is an HF implementation that, while it does not have all the features in NWChem, represents crucial algorithmic advances that reduce communication and improve load balance by doing an up-front static partitioning of tasks, followed by work stealing whenever necessary. To enable innovations in algorithms and exploit next generation exascale systems, it is crucial to support quantum chemistry codes using expressive and convenient programming models and runtime systems that are also efficient and scalable. This paper presents an HF implementation similar to GTFock using UPC++, a partitioned global address space model that includes flexible communication, asynchronous remote computation, and a powerful multidimensional array library. UPC++ offers runtime features that are useful for HF such as active messages, a rich calculus for array operations, hardware-supported fetch-and-add, and functions for ensuring asynchronous runtime progress. We present a new distributed array abstraction, DArray, that is convenient for the kinds of random-access array updates and linear algebra operations on block-distributed arrays with irregular data ownership. We analyze the performance of atomic fetch-and-add operations (relevant for load balancing) and runtime attentiveness, then compare various techniques and optimizations for each. Our optimized implementation of HF using UPC++ and the DArrays library shows up to 20% improvement over GTFock with Global Arrays at scales up to 24,000 cores.
H Shan, S Williams, Y Zheng, W Zhang, B Wang, S Ethier, Z Zhao, IEEE, "Experiences of Applying One-Sided Communication to Nearest-Neighbor Communication", PROCEEDINGS OF PAW 2016: 1ST PGAS APPLICATIONS WORKSHOP (PAW), January 2016, 17--24, doi: 10.1109/PAW.2016.008
- Download File: PAW16-stencil.pdf (pdf: 601 KB)
2015
Hongzhang Shan, Samuel Williams, Yili Zheng, Amir Kamil, Katherine Yelick,, "Implementing High-Performance Geometric Multigrid Solver with Naturally Grained Messages", 9th International Conference on Partitioned Global Address Space Programming Models (PGAS), September 2015, 38--46, doi: 10.1109/PGAS.2015.12
- Download File: pgas15-hpgmg.pdf (pdf: 803 KB)
Evangelos Georganas, Aydin Buluç, Jarrod Chapman, Leonid Oliker, Daniel Rokhsar, Katherine Yelick, "MerAligner: A Fully Parallel Sequence Aligner", IEEE 29th International Parallel and Distributed Processing Symposium (IPDPS), May 2015, 561--570, doi: 10.1109/IPDPS.2015.96
Aligning a set of query sequences to a set of target sequences is an important task in bioinformatics. In this work we present merAligner, a highly parallel sequence aligner that implements a seed -- and -- extend algorithm and employs parallelism in all of its components. MerAligner relies on a high performance distributed hash table (seed index) and uses one-sided communication capabilities of the Unified Parallel C to facilitate a fine-grained parallelism. We leverage communication optimizations at the construction of the distributed hash table and software caching schemes to reduce communication during the aligning phase. Additionally, merAligner preprocesses the target sequences to extract properties enabling exact sequence matching with minimal communication. Finally, we efficiently parallelize the I/O intensive phases and implement an effective load balancing scheme. Results show that merAligner exhibits efficient scaling up to thousands of cores on a Cray XC30 supercomputer using real human and wheat genome data while significantly outperforming existing parallel alignment tools.
Scott French, Yili Zheng, Barbara Romanowicz, Katherine Yelick, "Parallel Hessian Assembly for Seismic Waveform Inversion Using Global Updates", International Parallel and Distributed Processing Symposium (IPDPS), May 2015, 753--762, doi: 10.1109/IPDPS.2015.58
We present the design and evaluation of a distributed matrix-assembly abstraction for large-scale inverse problems in HPC environments: namely, physics-based Hessian estimation in full-waveform seismic inversion at the scale of the entire globe. Our solution to this data-assimilation problem relies on UPC++, a new PGAS extension to the C++ language, to implement one-sided asynchronous updates to distributed matrix elements, and allows us to tackle inverse problems well beyond our previous capabilities. Our evaluation includes scaling results for Hessian estimation on up to 12, 288 cores, typical of current production scientific runs and next-generation inversions. We also present comparisons with an alternative implementation based on MPI-3 remote memory access (RMA) operations, focusing on performance and code complexity. Interoperability between UPC ++ and other parallel programming tools (e.g. MPI, OpenMP) allowed for incremental adoption of the PGAS model where most beneficial. Further, we note that this model of asynchronous assembly can generalize to other data-assimilation applications that accumulate updates into shared global state.
Xuehai Qian, Koushik Sen, Paul Hargrove, Costin Iancu, "OPR: Partial Deterministic Record and Replay for One-Sided Communication", LBNL TR, April 17, 2015,
- Download File: main3.pdf (pdf: 295 KB)
Paul H. Hargrove, "Global Address Space Networking", Programming Models for Parallel Computing, edited by Pavan Balaji, (MIT Press: 2015)
2014
Vivek Kumar, Yili Zheng, Vincent Cavé, Zoran Budimlic, Vivek Sarkar, "HabaneroUPC++: a Compiler-free PGAS Library", 8th International Conference on Partitioned Global Address Space Programming Models (PGAS), October 2014,
Hongzhang Shan, Amir Kamil, Samuel Williams, Yili Zheng, Katherine Yelick, "Evaluation of PGAS Communication Paradigms with Geometric Multigrid", Proceedings of the 8th International Conference on Partitioned Global Address Space Programming Models (PGAS), October 2014, doi: 10.1145/2676870.2676874
- Download File: PGAS14-miniGMG.pdf (pdf: 1.2 MB)
Partitioned Global Address Space (PGAS) languages and one-sided communication enable application developers to select the communication paradigm that balances the performance needs of applications with the productivity desires of programmers. In this paper, we evaluate three different one-sided communication paradigms in the context of geometric multigrid using the miniGMG benchmark. Although miniGMG's static, regular, and predictable communication does not exploit the ultimate potential of PGAS models, multigrid solvers appear in many contemporary applications and represent one of the most important communication patterns. We use UPC++, a PGAS extension of C++, as the vehicle for our evaluation, though our work is applicable to any of the existing PGAS languages and models. We compare performance with the highly tuned MPI baseline, and the results indicate that the most promising approach towards achieving performance and ease of programming is to use high-level abstractions, such as the multidimensional arrays provided by UPC++, that hide data aggregation and messaging in the runtime library.
Amir Kamil, Yili Zheng, Katherine Yelick, "A Local-View Array Library for Partitioned Global Address Space C++ Programs", ACM SIGPLAN International Workshop on Libraries, Languages, and Compilers for Array Programming (ARRAY), June 2014,
Multidimensional arrays are an important data structure in many scientific applications. Unfortunately, built-in support for such arrays is inadequate in C++, particularly in the distributed setting where bulk communication operations are required for good performance. In this paper, we present a multidimensional library for partitioned global address space (PGAS) programs, supporting the one-sided remote access and bulk operations of the PGAS model. The library is based on Titanium arrays, which have proven to provide good productivity and performance. These arrays provide a local view of data, where each rank constructs its own portion of a global data structure, matching the local view of execution common to PGAS programs and providing maximum flexibility in structuring global data. Unlike Titanium, which has its own compiler with array-specific analyses, optimizations, and code generation, we implement multidimensional arrays solely through a C++ library. The main goal of this effort is to provide a library-based implementation that can match the productivity and performance of a compiler-based approach. We implement the array library as an extension to UPC++, a C++ library for PGAS programs, and we extend Titanium arrays with specializations to improve performance. We evaluate the array library by porting four Titanium benchmarks to UPC++, demonstrating that it can achieve up to 25% better performance than Titanium without a significant increase in programmer effort.
Yili Zheng, Amir Kamil, Michael B. Driscoll, Hongzhang Shan, Katherine Yelick, "UPC++: A PGAS extension for C++", International Parallel and Distributed Processing Symposium (IPDPS), May 19, 2014, 1105--1114, doi: 10.1109/IPDPS.2014.115
Partitioned Global Address Space (PGAS) languages are convenient for expressing algorithms with large, random-access data, and they have proven to provide high performance and scalability through lightweight one-sided communication and locality control. While very convenient for moving data around the system, PGAS languages have taken different views on the model of computation, with the static Single Program Multiple Data (SPMD) model providing the best scalability. In this paper we present UPC++, a PGAS extension for C++ that has three main objectives: 1) to provide an object-oriented PGAS programming model in the context of the popular C++ language, 2) to add useful parallel programming idioms unavailable in UPC, such as asynchronous remote function invocation and multidimensional arrays, to support complex scientific applications, 3) to offer an easy on-ramp to PGAS programming through interoperability with other existing parallel programming systems (e.g., MPI, OpenMP, CUDA). We implement UPC++ with a "compiler-free" approach using C++ templates and runtime libraries. We borrow heavily from previous PGAS languages and describe the design decisions that led to this particular set of language features, providing significantly more expressiveness than UPC with very similar performance characteristics. We evaluate the programmability and performance of UPC++ using five benchmarks on two representative supercomputers, demonstrating that UPC++ can deliver excellent performance at large scale up to 32K cores while offering PGAS productivity features to C++ applications.
2013
UPC Consortium, "UPC Language and Library Specifications, Version 1.3", Lawrence Berkeley National Laboratory Technical Report, November 16, 2013, LBNL 6623E, doi: 10.2172/1134233
UPC is an explicitly parallel extension to the ISO C 99 Standard. UPC follows the partitioned global address space programming model. This document is the formal specification for the UPC language and library syntax and semantics, and supersedes prior specification version 1.2 (LBNL-59208).
Chang-Seo Park, Koushik Sen, Costin Iancu, "Scaling Data Race Detection for Partitioned Global Address Space Programs", International Supercomputing Conference (ICS) 2013, 2013, doi: 10.1145/2464996.2465000
- Download File: thrille-exp4.pdf (pdf: 744 KB)
Contemporary and future programming languages for HPC promote hybrid parallelism and shared memory abstractions using a global address space. In this programming style, data races occur easily and are notoriously hard to find. Existing state-of-the-art data race detectors exhibit 10X-100X performance degradation and do not handle hybrid parallelism. In this paper we present the first complete implementation of data race detection at scale for UPC programs. Our implementation tracks local and global memory references in the program and it uses two techniques to reduce the overhead: 1) hierarchical function and instruction level sampling; and 2) exploiting the runtime persistence of aliasing and locality specific to Partitioned Global Address Space applications. The results indicate that both techniques are required in practice: well optimized instruction sampling introduces overheads as high as 6500% (65X slowdown), while each technique in separation is able to reduce it only to 1000% (10X slowdown). When applying the optimizations in conjunction our tool finds all previously known data races in our benchmark programs with at most 50% overhead when running on 2048 cores. Furthermore, while previous results illustrate the benefits of function level sampling, our experiences show that this technique does not work for scientific programs: instruction sampling or a hybrid approach is required.
Chang-Seo Park, Koushik Sen, Costin Iancu, "Scaling Data Race Detection for Partitioned Global Address Space Programs", Principles and Practice of Parallel Programming (PPoPP 2013), March 4, 2013,
- Download File: thrille-exp5.pdf (pdf: 200 KB)
2012
Michael Garland, Manjunath Kudlur, Yili Zheng, "Designing a Unified Programming Model for Heterogeneous Machines", Supercomputing (SC), November 2012, doi: 10.1109/SC.2012.48
While high-efficiency machines are increasingly embracing heterogeneous architectures and massive multithreading, contemporary mainstream programming languages reflect a mental model in which processing elements are homogeneous, concurrency is limited, and memory is a flat undifferentiated pool of storage. Moreover, the current state of the art in programming heterogeneous machines tends towards using separate programming models, such as OpenMP and CUDA, for different portions of the machine. Both of these factors make programming emerging heterogeneous machines unnecessarily difficult. We describe the design of the Phalanx programming model, which seeks to provide a unified programming model for heterogeneous machines. It provides constructs for bulk parallelism, synchronization, and data placement which operate across the entire machine. Our prototype implementation is able to launch and coordinate work on both CPU and GPU processors within a single node, and by leveraging the GASNet runtime, is able to run across all the nodes of a distributed-memory machine.
Evangelos Georganas, Jorge González-Domínguez, Edgar Solomonik, Yili Zheng, Juan Touriño, Katherine Yelick,, "Communication avoiding and overlapping for numerical linear algebra", International Conference for High Performance Computing, Networking, Storage and Analysis (SC), November 10, 2012, doi: 10.1109/SC.2012.32
To efficiently scale dense linear algebra problems to future exascale systems, communication cost must be avoided or overlapped. Communication-avoiding 2.5D algorithms improve scalability by reducing inter-processor data transfer volume at the cost of extra memory usage. Communication overlap attempts to hide messaging latency by pipelining messages and overlapping with computational work. We study the interaction and compatibility of these two techniques for two matrix multiplication algorithms (Cannon and SUMMA), triangular solve, and Cholesky factorization. For each algorithm, we construct a detailed performance model that considers both critical path dependencies and idle time. We give novel implementations of 2.5D algorithms with overlap for each of these problems. Our software employs UPC, a partitioned global address space (PGAS) language that provides fast one-sided communication. We show communication avoidance and overlap provide a cumulative benefit as core counts scale, including results using over 24K cores of a Cray XE6 system.
Paul H. Hargrove, UPC Language Full-day Tutorial, Workshop at UC Berkeley, July 12, 2012,
2011
George Almasi, Paul Hargrove, Gabriel Tanase and Yili Zheng, "UPC Collectives Library 2.0", Fifth Conference on Partitioned Global Address Space Programming Models (PGAS11), October 17, 2011,
Collective communication has been a part of the UPC standard since having been introduced in 2005 with the UPC Specification version 1.2. However, unlike MPI collectives, UPC collectives have never caught on and are rarely used.
In this paper we identify and discuss several fundamental limitations and important missing features in the design of the existing UPC collectives Next, we propose a new, consistent, portable and high performance collectives library that is aimed to augment UPC with a full complement of the collectives used by MPI. Ours is a pure library based approach; we change none of the functions in the existing UPC specification.that make them inconvenient to use and unsuitable for performance optimization.
We discuss the implementation requirements for this new UPC collectives library, and how our design attempts to minimize the implementation effort by enabling the reuse of existing collective implementations.
Rajesh Nishtala, Yili Zheng, Paul Hargrove, Katherine A. Yelick, "Tuning collective communication for Partitioned Global Address Space programming models", Parallel Computing, September 2011, 37(9):576--591, doi: 10.1016/j.parco.2011.05.006
Partitioned Global Address Space (PGAS) languages offer programmers the convenience of a shared memory programming style combined with locality control necessary to run on large-scale distributed memory systems. Even within a PGAS language programmers often need to perform global communication operations such as broadcasts or reductions, which are best performed as collective operations in which a group of threads work together to perform the operation. In this paper we consider the problem of implementing collective communication within PGAS languages and explore some of the design trade-offs in both the interface and implementation. In particular, PGAS collectives have semantic issues that are different than in send–receive style message passing programs, and different implementation approaches that take advantage of the one-sided communication style in these languages. We present an implementation framework for PGAS collectives as part of the GASNet communication layer, which supports shared memory, distributed memory and hybrids. The framework supports a broad set of algorithms for each collective, over which the implementation may be automatically tuned. Finally, we demonstrate the benefit of optimized GASNet collectives using application benchmarks written in UPC, and demonstrate that the GASNet collectives can deliver scalable performance on a variety of state-of-the-art parallel machines including a Cray XT4, an IBM BlueGene/P, and a Sun Constellation system with InfiniBand interconnect.
Paul H. Hargrove, UPC Language Half-day Tutorial, Workshop at UC Berkeley, June 15, 2011,
2010
Yili Zheng, "Optimizing UPC Programs for Multi-core Systems", Journal of Scientific Programming, 2010, 18(3-4):183-191, doi: 10.3233/SPR-2010-0310
- Download File: Zheng2010.pdf (pdf: 2.3 MB)
Paul H. Hargrove, Introduction to UPC, CScADS Workshop, July 21, 2010,
Costin Iancu, Steven Hofmeyr, Filip Blagojević, Yili Zheng, "Oversubscription on multicore processors", Proceedings of the 2010 IEEE International Symposium on Parallel and Distributed Processing (IPDPS), April 2010, doi: 10.1109/IPDPS.2010.5470434
- Download File: ovsub.pdf (pdf: 449 KB)
Existing multicore systems already provide deep levels of thread parallelism; hybrid programming models and composability of parallel libraries are very active areas of research within the scientific programming community. As more applications and libraries become parallel, scenarios where multiple threads compete for a core are unavoidable. In this paper we evaluate the impact of task oversubscription on the performance of MPI, OpenMP and UPC implementations of the NAS Parallel Benchmarks on UMA and NUMA multi-socket architectures. We evaluate explicit thread affinity management against the default Linux load balancing and discuss sharing and partitioning system management techniques. Our results indicate that oversubscription provides beneficial effects for applications running in competitive environments. Sharing all the available cores between applications provides better throughput than explicit partitioning. Modest levels of oversubscription improve system throughput by 27% and provide better performance isolation of applications from their co-runners: best overall throughput is always observed when applications share cores and each is executed with multiple threads per core. Rather than “resource” symbiosis, our results indicate that the determining behavioral factor when applications share a system is the granularity of the synchronization operations.
Yili Zheng, Filip Blagojevic, Dan Bonachea, Paul H. Hargrove, Steven Hofmeyr, Costin Iancu, Seung-Jai Min, Katherine Yelick, Getting Multicore Performance with UPC, SIAM Conference on Parallel Processing for Scientific Computing, February 2010,
- Download File: Multicore-Performance-with-UPC-SIAMPP10-Zheng.pdf (pdf: 933 KB)
Rajesh Nishtala, Yili Zheng, Paul H. Hargrove, Katherine Yelick, UPC at Scale, SIAM Conference on Parallel Processing for Scientific Computing, February 25, 2010,
Yili Zheng, Costin Iancu, Paul H. Hargrove, Seung-Jai Min, Katherine Yelick, Extending Unified Parallel C for GPU Computing, SIAM Conference on Parallel Processing for Scientific Computing, February 24, 2010,
2009
"Code controls communication to boost computer performance", Katherine Yelick, Paul Hargrove, Lawrence Berkeley National Laboratory CS Area Communications, August 27, 2009,
The Berkeley UPC compiler, backed by the GASNet communication system, are both developed at Berkeley Lab and UC Berkeley and provide computational scientists with a portable HPC programming model focused on high-performance one-sided communication.
Dan Bonachea, Paul Hargrove, Mike Welcome, Katherine Yelick, "Porting GASNet to Portals: Partitioned Global Address Space (PGAS) Language Support for the Cray XT", Cray Users Group (CUG), May 2009, doi: 10.25344/S4RP46
Partitioned Global Address Space (PGAS) Languages are an emerging alternative to MPI for HPC applications development. The GASNet library from Lawrence Berkeley National Lab and the University of California at Berkeley provides the network runtime for multiple implementations of four PGAS Languages: Unified Parallel C (UPC), Co-Array Fortran (CAF), Titanium and Chapel. GASNet provides a low overhead one-sided communication layer has enabled portability and high performance of PGAS languages. This paper describes our experiences porting GASNet to the Portals network API on the Cray XT series.
Rajesh Nishtala, Paul Hargrove, Dan Bonachea, Katherine Yelick, "Scaling Communication-Intensive Applications on BlueGene/P Using One-Sided Communication and Overlap", 23rd International Parallel & Distributed Processing Symposium (IPDPS), May 2009, doi: 10.1109/IPDPS.2009.5161076
In earlier work, we showed that the one-sided communication model found in PGAS languages (such as UPC) offers significant advantages in communication efficiency by decoupling data transfer from processor synchronization. We explore the use of the PGAS model on IBM Blue-Gene/P, an architecture that combines low-power, quad-core processors with extreme scalability. We demonstrate that the PGAS model, using a new port of the Berkeley UPC compiler and GASNet one-sided communication layer, outperforms two-sided (MPI) communication in both microbenchmarks and a case study of the communication-limited benchmark, NAS FT. We scale the benchmark up to 16,384 cores of the BlueGene/P and demonstrate that UPC consistently outperforms MPI by as much as 66% for some processor configurations and an average of 32%. In addition, the results demonstrate the scalability of the PGAS model and the Berkeley implementation of UPC, the viability of using it on machines with multicore nodes, and the effectiveness of the BG/P communication layer for supporting one-sided communication and PGAS languages.
2008
Paul H. Hargrove, Dan Bonachea, Christian Bell, Experiences Implementing Partitioned Global Address Space (PGAS) Languages on InfiniBand, OpenFabrics Alliance 2008 International Sonoma Workshop, April 2008,
2007
Hung-Hsun Su, Dan Bonachea, Adam Leko, Hans Sherburne, Max Billingsley III, Alan D. George, "GASP! A standardized performance analysis tool interface for global address space programming models", Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 4699 LNCS, December 1, 2007, doi: 10.1007/978-3-540-75755-9_54
The global address space (GAS) programming model provides important potential productivity advantages over traditional parallel programming models. Languages using the GAS model currently have insufficient support from existing performance analysis tools, due in part to their implementation complexity. We have designed the Global Address Space Performance (GASP) tool interface that is flexible enough to support instrumentation of any GAS programming model implementation, while simultaneously allowing existing performance analysis tools to leverage their tool's infrastructure and quickly add support for programming languages and libraries using the GAS model. To evaluate the effectiveness of this interface, the tracing and profiling overhead of a preliminary Berkeley UPC GASP implementation is measured and found to be within the acceptable range.
Parry Husbands, Katherine Yelick, "Multi-threading and one-sided communication in parallel LU factorization", Proceedings of the 2007 ACM/IEEE Conference on Supercomputing, SC 07, 2007, doi: 10.1145/1362622.1362664
Dense LU factorization has a high ratio of computation to communication and, as evidenced by the High Performance Linpack (HPL) benchmark, this property makes it scale well on most parallel machines. Nevertheless, the standard algorithm for this problem has non-trivial dependence patterns which limit parallelism, and local computations require large matrices in order to achieve good single processor performance. We present an alternative programming model for this type of problem, which combines UPC's global address space with lightweight multithreading. We introduce the concept of memory-constrained lookahead where the amount of concurrency managed by each processor is controlled by the amount of memory available. We implement novel techniques for steering the computation to optimize for high performance and demonstrate the scalability and portability of UPC with Teraflop level performance on some machines, comparing favourably to other state-of-the-art MPI codes.
Katherine Yelick, Dan Bonachea, Wei-Yu Chen, Phillip Colella, Kaushik Datta, Jason Duell, Susan L. Graham, Paul Hargrove, Paul Hilfinger, Parry Husbands, Costin Iancu, Amir Kamil, Rajesh Nishtala, Jimmy Su, Michael Welcome, Tong Wen, "Productivity and Performance Using Partitioned Global Address Space Languages", Proceedings of the 2007 International Workshop on Parallel Symbolic Computation (PASCO), July 2007, 24--32, doi: 10.1145/1278177.1278183
Partitioned Global Address Space (PGAS) languages combine the programming convenience of shared memory with the locality and performance control of message passing. One such language, Unified Parallel C (UPC) is an extension of ISO C defined by a consortium that boasts multiple proprietary and open source compilers. Another PGAS language, Titanium, is a dialect of Java T M designed for high performance scientific computation. In this paper we describe some of the highlights of two related projects, the Titanium project centered at U.C. Berkeley and the UPC project centered at Lawrence Berkeley National Laboratory. Both compilers use a source-to-source strategy that translates the parallel languages to C with calls to a communication layer called GASNet. The result is portable high-performance compilers that run on a large variety of shared and distributed memory multiprocessors. Both projects combine compiler, runtime, and application efforts to demonstrate some of the performance and productivity advantages to these languages.
Wei-Yu Chen, Dan Bonachea, Costin Iancu, Katherine A. Yelick, "Automatic nonblocking communication for partitioned global address space programs", Proceedings of the International Conference on Supercomputing (ICS), June 17, 2007, 158--167, doi: 10.1145/1274971.1274995
Overlapping communication with computation is an important optimization on current cluster architectures; its importance is likely to increase as the doubling of processing power far outpaces any improvements in communication latency. PGAS languages offer unique opportunities for communication overlap, because their one-sided communication model enables low overhead data transfer. Recent results have shown the value of hiding latency by manually applying language-level nonblocking data transfer routines, but this process can be both tedious and error-prone. In this paper, we present a runtime framework that automatically schedules the data transfers to achieve overlap. The optimization framework is entirely transparent to the user, and aggressively reorders and aggregates both remote puts and gets. We preserve correctness via runtime conflict checks and temporary buffers, using several techniques to lower the overhead. Experimental results on application benchmarks suggest that our framework can be very effective at hiding communication latency on clusters, improving performance over the blocking code by an average of 16% for some of the NAS Parallel Benchmarks, 48% for GUPS, and over 25% for a multi-block fluid dynamics solver. While the system is not yet as effective as aggressive manual optimization, it increases programmers' productivity by freeing them from the details of communication management.
Dan Bonachea, "Proposal for Extending the UPC Memory Copy Library Functions and Supporting Extensions to GASNet, v2.0", Lawrence Berkeley National Lab Tech Report, March 22, 2007, LBNL 56495 v2.0, doi: 10.2172/920052
This document outlines a proposal for extending UPC's point-to-point memcpy library with support for explicitly non-blocking transfers, and non-contiguous (indexed and strided) transfers. Various portions of this proposal could stand alone as independent extensions to the UPC library. The designs presented here are heavily influenced by analogous functionality which exists in other parallel communication systems, such as MPI, ARMCI, Titanium, and network hardware API's such as Quadrics elan, Infiniband vapi, IBM LAPI and Cray X-1. Each section contains proposed extensions to the libraries in the UPC Language Specification (section 7) and corresponding extensions to the GASNet communication system API.
Alfredo Buttari, Jack Dongarra, Parry Husbands, Jakub Kurzak, Katherine Yelick, Multithreading for synchronization tolerance in matrix factorization, Journal of Physics: Conference Series, 2007, doi: 10.1088/1742-6596/78/1/012028
Physical constraints such as power, leakage and pin bandwidth are currently driving the HPC industry to produce systems with unprecedented levels of concurrency. In these parallel systems, synchronization and memory operations are becoming considerably more expensive than before. In this work we study parallel matrix factorization codes and conclude that they need to be re-engineered to avoid unnecessary (and expensive) synchronization. We propose the use of multithreading combined with intelligent schedulers and implement representative algorithms in this style. Our results indicate that this strategy can significantly outperform traditional codes.
2006
Analysis of Partitioned Global Address Space Programs, Amir Kamil, M.S., December 2006,
- Download File: kamil-masters.pdf (pdf: 417 KB)
The introduction of multi-core processors by the major microprocessor vendors has brought parallel programming into the mainstream. Analysis of parallel languages is critical both for safety and optimization purposes. In this report, we consider the specific case of languages with barrier synchronization and global address space abstractions. Two of the fundamental problems in the analysis of parallel programs are to determine when two statements in a program can execute concurrently, and what data can be referenced by each memory location. We present an efficient interprocedural analysis algorithm that conservatively computes the set of all concurrent statements, and improve its precision by using context-free language reachability to ignore infeasible program paths. In addition, we describe a pointer analysis using a hierarchical machine model, which distinguishes between pointers that can reference values within a thread, within a shared memory multiprocessor, or within a network of processors. We then apply the analyses to two clients, data race detection and memory model enforcement. Using a set of five benchmarks, we show that both clients benefit significantly from the analyses.
Dan Bonachea, Rajesh Nishtala, Paul Hargrove, Mike Welcome, Kathy Yelick,, "Optimized Collectives for PGAS Languages with One-Sided Communication", ACM/IEEE Conference on Supercomputing (SC'06) Poster Session, November 2006, doi: 10.1145/1188455.1188604
Optimized collective operations are a crucial performance factor for many scientific applications. This work investigates the design and optimization of collectives in the context of Partitioned Global Address Space (PGAS) languages such as Unified Parallel C (UPC). Languages with one-sided communication permit a more flexible and expressive collective interface with application code, in turn enabling more aggressive optimization and more effective utilization of system resources. We investigate the design tradeoffs in a collectives implementation for UPC, ranging from resource management to synchronization mechanisms and target-dependent selection of optimal communication patterns. Our collectives are implemented in the Berkeley UPC compiler using the GASNet communication system, tuned across a wide variety of supercomputing platforms, and benchmarked against MPI collectives. Special emphasis is placed on the newly added Cray XT3 backend for UPC, whose characteristics are benchmarked in detail.
Dan Bonachea, Rajesh Nishtala, Paul Hargrove, Katherine Yelick, Efficient Point-to-point Synchronization in UPC, 2nd Conf. on Partitioned Global Address Space Programming Models (PGAS06), October 4, 2006,
- Download File: upc-sem-0.2.pdf (pdf: 174 KB)
- Download File: PGAS06-p2p.pdf (pdf: 945 KB)
- Download File: UPC-p2p-abstract.pdf (pdf: 37 KB)
2005
Dan O Bonachea, Christian Bell, Rajesh Nishtala, Kaushik Datta, Parry Husbands, Paul Hargrove, Katherine Yelick, "The Performance and Productivity Benefits of Global Address Space Languages", ACM/IEEE Conference on Supercomputing (SC'05) Poster Session, November 2005,
Costin Iancu, Parry Husbands, Paul Hargrove, "HUNTing the Overlap", IEEE Parallel Architectures and Compilation Techniques (PACT), September 2005, doi: 10.1109/PACT.2005.25
Hiding communication latency is an important optimization for parallel programs. Programmers or compilers achieve this by using non-blocking communication primitives and overlapping communication with computation or other communication operations. Using non-blocking communication raises two issues: performance and programmability. In terms of performance, optimizers need to find a good communication schedule and are sometimes constrained by lack of full application knowledge. In terms of programmability, efficiently managing non-blocking communication can prove cumbersome for complex applications. In this paper we present the design principles of HUNT, a runtime system designed to search and exploit some of the available overlap present at execution time in UPC programs. Using virtual memory support, our runtime implements demand-driven synchronization for data involved in communication operations. It also employs message decomposition and scheduling heuristics to transparently improve the non-blocking behavior of applications. We provide a user level implementation of HUNT on a variety of modern high performance computing systems. Results indicate that our approach is successful in finding some of the overlap available at execution time. While system and application characteristics influence performance, perhaps the determining factor is the time taken by the CPU to execute a signal handler. Demand driven synchronization at execution time eliminates the need for the explicit management of non-blocking communication. Besides increasing programmer productivity, this feature also simplifies compiler analysis for communication optimizations.
UPC Consortium, "UPC Language Specifications, v1.2", Lawrence Berkeley National Laboratory Technical Report, May 31, 2005, LBNL 59208, doi: 10.2172/862127
UPC is an explicitly parallel extension to the ISO C 99 Standard. UPC follows the partitioned global address space programming model. This document is the formal specification for the UPC language syntax and semantics.
WY Chen, C Iancu, K Yelick, "Communication optimizations for fine-grained UPC applications", Parallel Architectures and Compilation Techniques - Conference Proceedings, PACT, 2005, 2005:267--272, doi: 10.1109/PACT.2005.13
2004
Christian Bell, Dan Bonachea, Wei-Yu Chen, Katherine Yelick, "Evaluating Support for Global Address Space Languages on the Cray X1", Proceedings of the International Conference on Supercomputing (ICS), November 22, 2004, 184--195, doi: 10.1145/1006209.1006236
The Cray X1 was recently introduced as the first in a new line of parallel systems to combine high-bandwidth vector processing with an MPP system architecture. Alongside capabilities such as automatic fine-grained data parallelism through the use of vector instructions, the X1 offers hardware support for a transparent global-address space (GAS), which makes it an interesting target for GAS languages. In this paper, we describe our experience with developing a portable, open-source and. high performance compiler for Unified Parallel C (UPC), a SPMD global-address space language extension of ISO C. As part of our implementation effort, we evaluate the X1's hardware support for GAS languages and provide empirical performance characterizations in the context of leveraging features such as vectorization and global pointers for the Berkeley UPC compiler. We discuss several difficulties encountered in the Cray C compiler which are likely to present challenges for many users, especially implementors of libraries and source-to-source translators. Finally, we analyze the performance of our compiler on some benchmark programs and show that, while there are some limitations of the current compilation approach, the Berkeley UPC compiler uses the X1 network more effectively than MPI or SHMEM, and generates serial code whose vectorizability is comparable to the original C code.
Christian Bell, Dan Bonachea, Wei Chen, Jason Duell, Paul Hargrove, Parry Husbands, Costin Iancu, Wei Tu, Mike Welcome, Kathy Yelick, "GASNet 2 - An Alternative High-Performance Communication Interface", ACM/IEEE Conference on Supercomputing (SC'04) Poster Session, November 2004,
Costin Iancu, Parry Husbands, Wei Chen, "Message Strip-Mining Heuristics for High Speed Networks", VECPAR, 2004, doi: 10.1007/11403937_33
In this work we investigate how the compiler technique of message strip-mining performs in practice on contemporary high performance networks. Message strip-mining attempts to reduce the overall cost of communication in parallel programs by breaking up large message transfers into smaller ones that can be overlapped with computation. In practice, however, network resource constraints may negate the expected performance gains. By deriving a performance model and synthetic benchmarks we determine how network and application characteristics influence the applicability of this optimization. We use these findings to determine heuristics to follow when performing this optimization on parallel programs. We propose strip-mining with variable block size as an alternative strategy that performs almost as well as a highly tuned fixed block strategy and has the advantage of being performance portable across systems and application input sets. We evaluate both techniques using synthetic benchmarks and an application from the NAS Parallel Benchmark suite.
Katherine Yelick, Dan Bonachea, Charles Wallace, "A Proposal for a UPC Memory Consistency Model, v1.0", Lawrence Berkeley National Laboratory Technical Report, May 5, 2004, LBNL 54983, doi: 10.2172/823757
The memory consistency model in a language defines the order in which the results of write operations maybe observed through read operations. The behavior of a UPC program may depend on the timing of accesses to shared variables, so a program defines a set of possible executions, rather than a single execution. The memory consistency model constrains the set of possible executions for a given program; the user may then rely on properties that are true of all of those executions.The memory consistency model is defined in terms of the read and write operations issued by each thread in naive translation of the code, i.e., without any code transformations by the compiler – with each thread issuing operations as defined by the abstract machine defined in ISO C 5.1.2.3. A UPC compiler or runtime system may perform various code transformations to improve performance, so long as they are not visible to the programmer – i.e. provided the set of externally-visible behaviors (the input/output dynamics and volatile behavior defined in ISO C 5.1.2.3) from any execution of the transformed program are identical to those of the original program executing on the abstract machine and adhering to the consistency model defined in this document.
Dan Bonachea, Jason Duell, "Problems with using MPI 1.1 and 2.0 as compilation targets for parallel language implementations", International Journal of High Performance Computing and Networking, January 2004, 1(1-3):91-99, doi: 10.1504/IJHPCN.2004.007569
MPI support is nearly ubiquitous on high-performance systems today and is generally highly tuned for performance. It would thus seem to offer a convenient ‘portable network assembly language’ to developers of parallel programming languages who wish to target different network architectures. Unfortunately, neither the traditional MPI 1.1 API nor the newer MPI 2.0 extensions for one-sided communication provide an adequate compilation target for global address space languages, and this is likely to be the case for many other parallel languages as well. Simulating one-sided communication under the MPI 1.1 API is too expensive, while the MPI 2.0 one-sided API imposes a number of significant restrictions on memory access patterns that would need to be incorporated at the language level, as a compiler cannot effectively hide them given current conflict and alias detection algorithms.
2003
Dan Bonachea, Bill Carlson, Jason Duell, Steve Seidel, Brian Wibecan, "UPC Collective Operations Specifications, V1.0", UPC Consortium, December 12, 2003, doi: 10.25344/S4TS3G
Christian Bell, Dan Bonachea, Wei Chen, Jason Duell, Paul Hargrove, Parry Husbands, Costin Iancu, Mike Welcome, Kathy Yelick, "GASNet: Project Overview (SC'03)", ACM/IEEE Conference on Supercomputing (SC'03) Poster Session, November 2003,
Dan Bonachea, Jason Duell, "Problems with using MPI 1.1 and 2.0 as compilation targets for parallel language implementations (conference version)", 2nd Workshop on Hardware/Software Support for High Performance Scientific and Engineering Computing, SHPSEC-PACT03, September 27, 2003, doi: 10.25344/S4JP4B
MPI support is nearly ubiquitous on high performance systems today, and is generally highly tuned for performance. It would thus seem to offer a convenient “portable network assembly language” to developers of parallel programming languages who wish to target different network architectures. Unfortunately, neither the traditional MPI 1.1 API, nor the newer MPI 2.0 extensions for one-sided communication provide an adequate compilation target for global address space languages, and this is likely to be the case for many other parallel languages as well. Simulating one-sided communication under the MPI 1.1 API is too expensive, while the MPI 2.0 one-sided API imposes a number of significant restrictions on memory access patterns that that would need to be incorporated at the language level, as a compiler can not effectively hide them given current conflict and alias detection algorithms.
Wei Chen, Dan Bonachea, Jason Duell, Parry Husbands, Costin Iancu, Katherine Yelick,, "A Performance Analysis of the Berkeley UPC Compiler", Proceedings of the International Conference on Supercomputing (ICS), ACM, June 23, 2003, 63--73, doi: 10.1145/782814.782825
Unified Parallel C (UPC) is a parallel language that uses a Single Program Multiple Data (SPMD) model of parallelism within a global address space. The global address space is used to simplify programming, especially on applications with irregular data structures that lead to fine-grained sharing between threads. Recent results have shown that the performance of UPC using a commercial compiler is comparable to that of MPI [7]. In this paper we describe a portable open source compiler for UPC. Our goal is to achieve a similar performance while enabling easy porting of the compiler and runtime, and also provide a framework that allows for extensive optimizations. We identify some of the challenges in compiling UPC and use a combination of micro-benchmarks and application kernels to show that our compiler has low overhead for basic operations on shared data and is competitive, and sometimes faster than, the commercial HP compiler. We also investigate several communication optimizations, and show significant benefits by hand-optimizing the generated code.
Christian Bell, Dan Bonachea, Yannick Cote, Jason Duell, Paul Hargrove, Parry Husbands, Costin Iancu, Michael L. Welcome, Katherine A. Yelick, "An Evaluation of Current High-Performance Networks", Proceedings of the International Parallel & Distributed Processing Symposium (IPDPS), April 22, 2003, doi: 10.1109/IPDPS.2003.1213106
High-end supercomputers are increasingly built out of commodity components, and lack tight integration between the processor and network. This often results in inefficiencies in the communication subsystem, such as high software overheads and/or message latencies. In this paper we use a set of microbenchmarks to quantify the cost of this commoditization, measuring software overhead, latency, and bandwidth on five contemporary supercomputing networks. We compare the performance of the ubiquitous MPI layer to that of lower-level communication layers, and quantify the advantages of the latter for small message performance. We also provide data on the potential for various communication-related optimizations, such as overlapping communication with computation or other communication. Finally, we determine the minimum size needed for a message to be considered 'large' (i.e., bandwidth-bound) on these platforms, and provide historical data on the software overheads of a number of supercomputers over the past decade.
2002
Christian Bell, Dan Bonachea, Wei Chen, Jason Duell, Paul Hargrove, Parry Husbands, Costin Iancu, Mike Welcome, Kathy Yelick, "GASNet: Project Overview (SC'02)", ACM/IEEE Conference on Supercomputing (SC'02) Poster Session, November 2002,
Dan Bonachea, "GASNet Specification, v1.1", University of California, Berkeley Tech Report UCB/CSD-02-1207, October 28, 2002, doi: 10.25344/S4MW28
This document has been superseded by: GASNet Specification, v1.8.1 (LBNL-2001064)
This GASNet specification describes a network-independent and language-independent high-performance communication interface intended for use in implementing the runtime system for global address space languages (such as UPC or Titanium).