






New Encoder-Decoder Overcomes Limitations in Scientific Machine Learning
Deep Learning Framework with CRF Model Solves Both Segmentation and Adaptability Problems
May 2, 2022
By Carol Pott
Contact: cscomms@lbl.gov
Thanks to recent improvements in machine and deep learning, computer vision has contributed to the advancement of everything from self-driving cars and traffic flow analysis to cancer detection and medical imaging. Using deep learning semantic segmentation, a method that labels each pixel of an image, computers have surpassed humans in solving classic image classification, detection, and segmentation problems. Despite many advancements, there is an increasing need for powerful, user-friendly software to push the state-of-the-art of this field further. However, for use with increasingly large and complex scientific datasets, like those coming from Department of Energy (DOE) user facilities, the inflexibility of these software frameworks prevents widespread adoption.
Motivated by these challenges, a team of Lawrence Berkeley National Laboratory (Berkeley Lab) computational researchers led by Talita Perciano from the Scientific Data Division (SDD)’s Machine Learning and Analytics Group introduced a new Python-based encoder-decoder framework that overcomes both the segmentation and widespread adaptability problems. Their work was published recently in the journal Advances in Artificial Intelligence and Machine Learning.
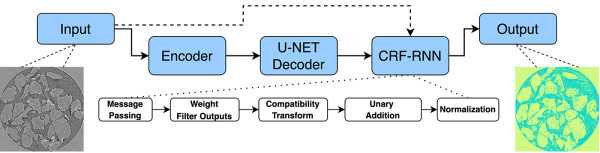
Figure: A general depiction of the encoder-decoder framework with an integrated CRF-RNN layer. The input data is fed into a chosen encoder, which then is upsampled by the U-Net-based decoder. Both the decoder output and the initial image serve as inputs for the CRF-RNN layer, which produces the final pixel-based prediction. (Credit: M. Avaylon, T. Perciano, Z. Bai)
Recent advances using conditional random fields (CRFs) and convolutional neural networks (CNNs) to analyze visual imagery boosted the results of pixel-level image classification and, using a fully integrated CRF-recurrent neural network (CRF-RNN) layer, showed significant segmentation advantages. However, no existing framework fully addresses the growing data requirements of research scientists until now.
In deep learning, a CNN is an artificial neural network that is based on a collection of connected nodes called artificial neurons which are inspired by the biological neural networks that make up animal brains. Much like the synapses in a biological brain, each connection transmits a signal to other neurons who receive that signal and then process it and signal the neurons connected to it. Backpropagation acts as the messenger telling the neural network whether or not it made a prediction error.
The Berkeley Lab team was able to adapt multiple CNNs as encoders, allowing for the definition of several functions and parameter arguments to fine-tune the models to targeted datasets and scientific problems. Leveraging the flexibility of the U-Net architecture (U-Net is a CNN that was developed specifically for biomedical image segmentation) to act as a scalable decoder and integrating the CRF-RNN layer into the decoder as an optional final layer, the entire system is kept fully compatible with backpropagation. The addition of the CRF-RNN layer becomes essential for machine learning applied to scientific data because it incorporates prior knowledge through a graph-based model and allows for an end-to-end training process for semantic segmentation and backpropagation.
Putting the Framework to the Test
To evaluate the performance of the implementation, the team performed experiments using both the Oxford-IIIT Pet Dataset and experimental micro-computed tomography (microCT) data obtained at the ALS Beamline 8.3.2, showing the performance benefits and adaptability of this software as a fully end-to-end CNN-CRF system.
“Our new encoder-decoder system is not only an initial step toward creating a user-friendly, pixel-level segmentation package that includes both convolutional and graphical models,” said Talita Perciano, research scientist, SDD, “but also further demonstrates the viability of CRFs to improve performance on traditional CNNs on scientific data.”
Their publicly available framework uses three main deep learning architectures for the encoder part of the network: ResNet-50, VGG-16, and U-Net. The original decoder, a full convolutional network FCN-8s, performed well but lacked the ability to scale across different encoder options or adjust to image sizes beyond the original 500✕500 size. As a result, the team implemented a new decoder based on U-Net architecture. Their new U-Net-based decoder scales to various encoder sizes and allows users more options for larger image dimensions.
“When I joined the project, the goal was to get preliminary results with just U-Net on the binary synthetic data and then get results with U-Net with the CRF on the same dataset,'' said Matthew Avaylon, machine learning engineer, SDD. “After we saw that it improves both the individual class level and the rate of convergence, we wanted to see how it compares to other state-of-the-art models, with the end goal to create a software system that houses a flexible encoder-decoder architecture.”
The team also ran experiments at the National Energy Research Scientific Computing Center (NERSC) to show that the framework can also be executed on GPUs. Using the Cori system, the team compared the training performance of dual-socket, 20-core Xeon (Skylake) CPUs against Cori’s eight NVIDIA V100 GPUs and found that Cori delivered three to four times faster performance. For instance, on synthetic binary data, the eight GPUs required an average of two seconds per step and 156 minutes of total training time, compared to six seconds per step and 486 minutes of total time on the Xeons.
“The CRF layer is computationally expensive to train conventionally, and we embraced a GPU-accelerator approach to AI model training in this integrated neural network,” said Zhe Bai, postdoctoral scholar, SDD. “With the Oxford-Pet IIIT data, the GPU-accelerated node completed 20 epochs of training in 2,050 minutes (34 hours). This reduced training time by two days when compared with the CPU-based implementation, while attaining a statistically similar accuracy of 87% for the U-Net-CRF model.”
This research is supported by the Laboratory Directed Research and Development Program at Lawrence Berkeley National Laboratory under U.S. Department of Energy Contract No. DE-AC02-05CH11231.
About Berkeley Lab
Founded in 1931 on the belief that the biggest scientific challenges are best addressed by teams, Lawrence Berkeley National Laboratory and its scientists have been recognized with 16 Nobel Prizes. Today, Berkeley Lab researchers develop sustainable energy and environmental solutions, create useful new materials, advance the frontiers of computing, and probe the mysteries of life, matter, and the universe. Scientists from around the world rely on the Lab’s facilities for their own discovery science. Berkeley Lab is a multiprogram national laboratory, managed by the University of California for the U.S. Department of Energy’s Office of Science.
DOE’s Office of Science is the single largest supporter of basic research in the physical sciences in the United States, and is working to address some of the most pressing challenges of our time. For more information, please visit energy.gov/science.