






Berkeley Lab Researchers Make NWChem’s Planewave “Purr” on Intel’s Knights Landing Architectures
Now larger, more complex chemical processes can be modeled in less time
March 21, 2017
Linda Vu, lvu@lbl.gov, +1 510.495.2402
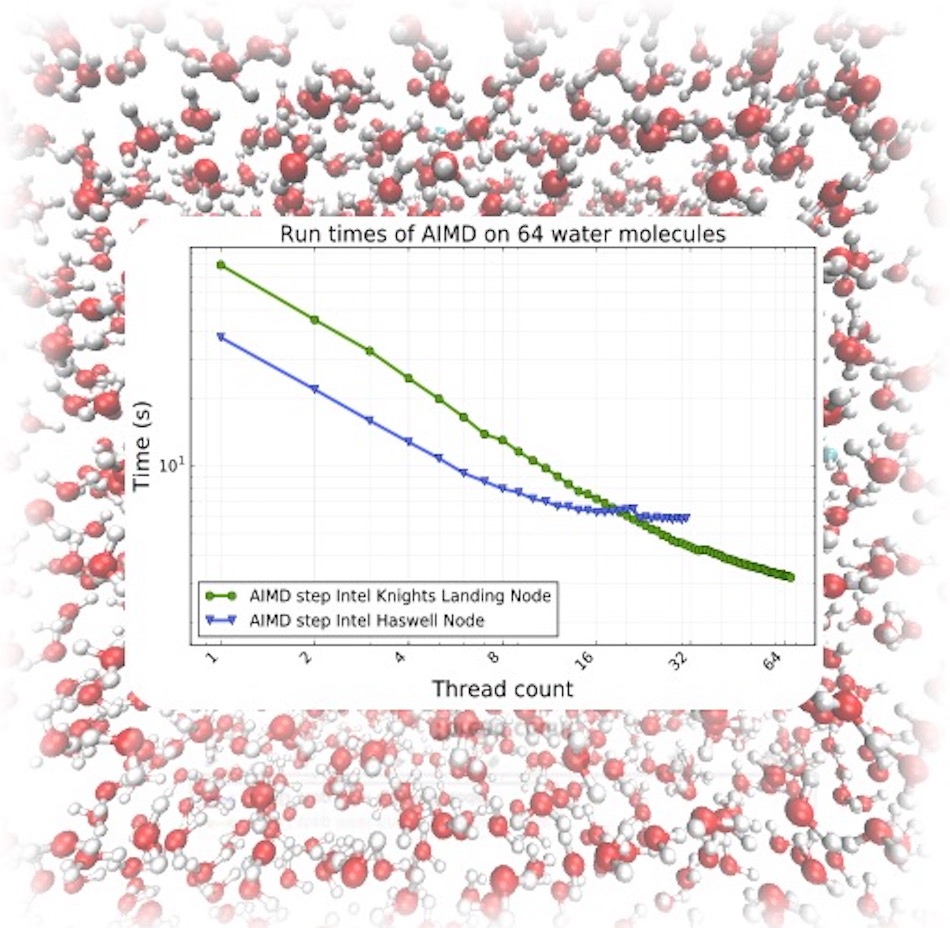
OpenMP optimized NWChem AIMD plane wave code is demonstrated to run faster on a single Intel Knights Landing node when compared to a conventional Intel Haswell node. The simulation run consists of 64 water molecule.
A team of researchers at the Lawrence Berkeley National Laboratory (Berkeley Lab), Pacific Northwest National Laboratory (PNNL) and Intel are working hard to make sure that computational chemists are prepared to compute efficiently on next-generation exascale machines. Recently, they achieved a milestone, successfully adding thread-level parallelism on top of MPI-level parallelism in the planewave density functional theory method within the popular software suite NWChem.
“Planewave codes are useful for solution chemistry and materials science; they allow us to look at the structure, coordination, reactions and thermodynamics of complex dynamical chemical processes in solutions and on surfaces,” says Bert de Jong, a computational chemist in the Computational Research Division (CRD) at Berkeley Lab.
Developed approximately 20 years ago, the open-source NWChem software was designed to solve challenging chemical and biological problems using large-scale parallel ab initio, or first principle calculations. De Jong and his colleagues will present a paper on this latest parallelization work at the May 29-June 2 IEEE International Parallel and Distributed Processing Symposium in Orlando, Florida.
Multicore vs. “Manycore”: Preparing Science for Next-Generation HPC
Since the 1960s, the semiconductor industry has looked to Moore’s Law—the observation that the number of transistors on a microprocessor chip doubles about every two years—to set targets for their research and development. As a result, chip performance sped up considerably, eventually giving rise to laptop computers, smartphones and the Internet. But like all good things, this couldn’t last.
As more and more silicon circuits are packed into the same small area, an increasingly unwieldy amount of heat is generated. So about a decade ago, microprocessor designers latched onto the idea of multicore architectures—putting multiple processors called “cores” on a chip—similar to getting five people to carry your five bags of groceries home, rather than trying to get one stronger person to go five times faster and making separate trips for each bag.
Supercomputing took advantage of these multicore designs, but today they are still proving too power-hungry, and instead designers are using a larger number of smaller, simpler processor cores in the newest supercomputers. This “manycore” approach—akin to a small platoon of walkers rather than a few runners—will be taken to an extreme in future exaflop supercomputers. But achieving a high level of performance on these manycore architectures requires rewriting software, incorporating intensive thread and data-level parallelism and careful orchestration of data movement. In the grocery analogy, this addresses who will carry each item, can the heavier ones be divided into smaller parts, and should items be handed around mid-way to avoid overtiring anyone—more like a squad of cool, slow-walking, collaborative jugglers.
Getting Up to Speed on Manycore
The first step to ensuring that their codes will perform efficiently on future exascale supercomputers is to make sure that they are taking full advantage of manycore architectures that are being deployed. De Jong and his colleagues have been working for over a year to get the NWChem planewave code optimized and ready for science, just in time for the arrival of NERSC latest supercomputer Cori.
The recently installed Cori system at the Department of Energy’s (DOE’s) National Energy Research Scientific Computing Center (NERSC) reflects one of these manycore designs. It contains about 9,300 Intel Xeon Phi (Knights Landing) processors and according to the November, 2016 Top500 list, is the largest system of its kind, also representing NERSC’s move towards exascale. de Jong and his colleagues were able to gain early access to Cori through the NERSC Exascale Science Applications Program and the new NWChem code has been shown to perform well on the new machine.
According to de Jong, the NWChem planewave methods primarily comprise fast Fourier transform (FFT) algorithms and matrix multiplications of tall-skinny matrix products. Because current Intel math libraries don’t efficiently solve the tall-skinny matrix products in parallel, Mathias Jacquelin, a scientist in CRD’s Scalable Solvers Group, developed a parallel algorithm and optimized manycore implementation for calculating these matrices and then integrated that into the existing planewave codes.
When trying to squeeze the most performance from new architectures, it is helpful to understand how much headroom is left—how close are you to computing or data movement limits of the hardware, and when will you reach the point of diminishing returns in tuning an application’s performance. For this, Jacquelin turned to a tool known as a Roofline Model, developed several years ago by CRD computer scientist Sam Williams.
Jacquelin developed an analysis of matrix factorization routine within a roofline model for the Knights Landing nodes. In a test case that simulated a solution with 64 water molecules, the team found that their code easily scaled up to all 68 cores available in a single massively parallel Intel Xeon Phi Knights Landing node. They also found that the new, completely threaded version of the planewave code performed three times faster on this manycore architecture than on current generations of the Intel Xeon cores, which will allow computational chemists to model larger, more complex chemical systems in less time.
“Our achievement is especially good news for researchers who use NWChem because it means that they can exploit multicore architectures of current and future supercomputers in an efficient way,” says Jacquelin. “Because there are other areas of chemistry that also rely on tall-skinny matrices, I believe that our work could potentially be applied to those problems as well.”
“Getting this level of performance on the Knights Landing architecture is a real accomplishment and it took a team effort to get there,” says de Jong. “Next, we will be focusing on running some large scale simulations with these codes.”
This work was done with support from DOE’s Office of Science and Intel’s Parallel Computing Center at Berkeley Lab. NERSC is a DOE Office of Science User Facility. In addition to de Jong and Jacquelin, Eric Bylaska of PNNL was also a co-author on the paper.
About Berkeley Lab
Founded in 1931 on the belief that the biggest scientific challenges are best addressed by teams, Lawrence Berkeley National Laboratory and its scientists have been recognized with 16 Nobel Prizes. Today, Berkeley Lab researchers develop sustainable energy and environmental solutions, create useful new materials, advance the frontiers of computing, and probe the mysteries of life, matter, and the universe. Scientists from around the world rely on the Lab’s facilities for their own discovery science. Berkeley Lab is a multiprogram national laboratory, managed by the University of California for the U.S. Department of Energy’s Office of Science.
DOE’s Office of Science is the single largest supporter of basic research in the physical sciences in the United States, and is working to address some of the most pressing challenges of our time. For more information, please visit energy.gov/science.