






CRD’s Ibrahim Cracks Graph500 with Precisely Tuned Data-Intensive Algorithms
December 8, 2016
Khaled Ibrahim's contributions to the top 10 of the Graph500 are highlighted at SC16.
In the world of high performance computing, there are benchmarks and then there are other benchmarks. Thanks to the TOP500 list, now in its 24th year, the LINPACK benchmark has become the most visible, as all 500 systems on the twice-yearly list are ranked by how will they run LINPACK, which was a benchmark developed in the early 1980s to represent common computational needs of that era of supercomputing.
But many have argued that LINPACK represents an anachronistic view of a real-world computational problem and its value is therefore limited. Benchmarks are only useful insofar as they represent the needs of the real application workload that will be using the system. Over the past decade, other benchmarks have emerged with an eye toward producing a more real-world look at a system’s performance and then using that a ranking basis.
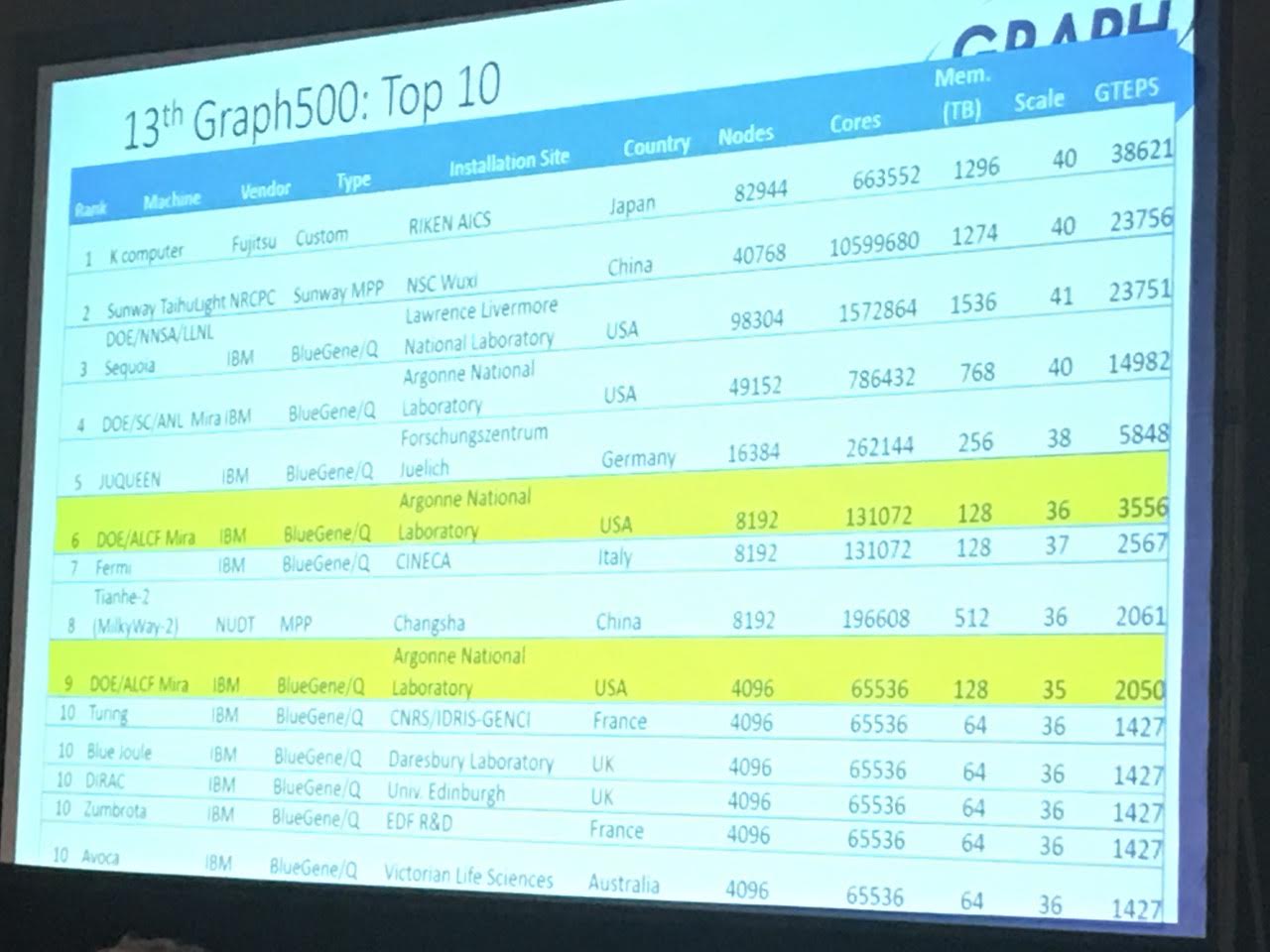
The Graph 500 list ranks the performance of systems running emerging data-intensive workloads using graph analytics algorithms, which stress the internal communications subsystem of the supercomputer. When the latest version of the Graph 500 list was released Nov. 16 at the SC16 conference, there were two new entries in the top 10, both contributed by Khaled Ibrahim of Berkeley Lab’s Computational Research Division.

Khaled Ibrahim
Ibrahim explains that such workloads, known as communication-bound applications are typically the most difficult to scale on HPC systems. But finding a way to scale up their performance can have a big payoff by reducing the computational “expense,” or amount of computing time needed to solve a problem.
Two factors affect the performance of such applications: the capability of the system itself and the algorithm used. The algorithm in turn is influenced by the runtime system and programming model used to develop it.
“The goal is to get the best performance possible on a specific machine and we do this by creating the best algorithm to solve a specific problem on that machine,” Ibrahim said. “On the algorithmic side, the challenge that graph analytic algorithms pose is that the data movements are naturally irregular and fine-grained. This makes it difficult to efficiently orchestrate communication at large-scale systems.”
A Precision Method
Ibrahim achieved his results using an approach he calls “precision runtime,” which he likens to precision medicine. Rather than trying to improve the entire application, he focused on the runtime component of critical computational kernels. For his work, he was granted access to a portion of Mira, and IBM BlueGene/Q supercomputer at Argonne National Laboratory.
Using eight of Mira’s 48 racks, which translates to 131,072 processor cores, Ibrahim attained the sixth spot on the list by achieving 3,556 GTEPS, or giga-traversed edges per second, the performance metric for the Graph 500. Using four racks (65,536 processor cores), he achieved 2,050 GTEPS “These submissions significantly improve on prior submissions from IBM,” Ibrahim said.
GTEPS refers to the number of edges, or connections, between vertices in the problem. One way to think about this is using Facebook – each person with a Facebook account is a vertex and each connection between each of those users is an edge. In November 2016, Facebook had 1.79 billion active monthly users (vertices), each of whom had an average of 155 friends, yielding more than 277 billion edges.
Although Ibrahim notched two of the top 10 spots of the Graph 500, “the submission that I am particularly proud of is for a single rack, delivering 705 GTEPS compared with the best performance achieved previously at 382 GTEPS – an 80 percent increase,” he said, which was ranked at number 28. “To put things into context, the vertex count in this problem is more than twice the number of Facebook accounts.”
Because of the precision nature of his work, Ibrahim said, customizing an application really only makes sense for large-scale applications and where overall performance is critical to the kind of science being performed, but he’s shown he can gain improvements of five to 10 times the performance over general purpose runtimes. Critical to his success was the access and support provided by Adam Scovel and other members of the Argonne Leadership Computing Facility staff.
Perhaps one indication of the difficulty of this effort is that although the list claims to be the Graph500, only 220 results were listed in the latest edition.
This was not the first time Ibrahim’s precision tuning work made a splash at the SC conference. At SC14, his expertise helped him win the HPC Challenge for the fastest performance of a Fast Fourier Transformation (FFT) application. He tuned his application to achieve 226 teraflop/s, also running on Mira. His result was 9.7 percent faster than the runner-up, which ran on Japan’s K computer.
No Clear Path
One of the challenges Ibrahim faces in this area is that there are many paths to optimizing the algorithm’s performance. The work requires getting familiar with the system in question, and then focus on the algorithm.
“You really have to think outside the box, but when you do that you can get lost,” he said. “The open dimensions of optimization can be confusing and if you don’t know the specifics of the machine you can waste a lot of time – you could even end up with slower performance.”
Fortunately, he said, the IBM machines are open to all kinds of exploration, but he’s hoping to explore systems built by other vendors in the future.
“Ideally, we can take what we learn now and use that knowledge to develop better standards in the future that can benefit all codes,” he said.
About Berkeley Lab
Founded in 1931 on the belief that the biggest scientific challenges are best addressed by teams, Lawrence Berkeley National Laboratory and its scientists have been recognized with 16 Nobel Prizes. Today, Berkeley Lab researchers develop sustainable energy and environmental solutions, create useful new materials, advance the frontiers of computing, and probe the mysteries of life, matter, and the universe. Scientists from around the world rely on the Lab’s facilities for their own discovery science. Berkeley Lab is a multiprogram national laboratory, managed by the University of California for the U.S. Department of Energy’s Office of Science.
DOE’s Office of Science is the single largest supporter of basic research in the physical sciences in the United States, and is working to address some of the most pressing challenges of our time. For more information, please visit energy.gov/science.