






New Math Methods and Perlmutter HPC Combine to Deliver Record-Breaking ML Algorithm
March 13, 2023
By Elizabeth Ball
Contact: cscomms@lbl.gov
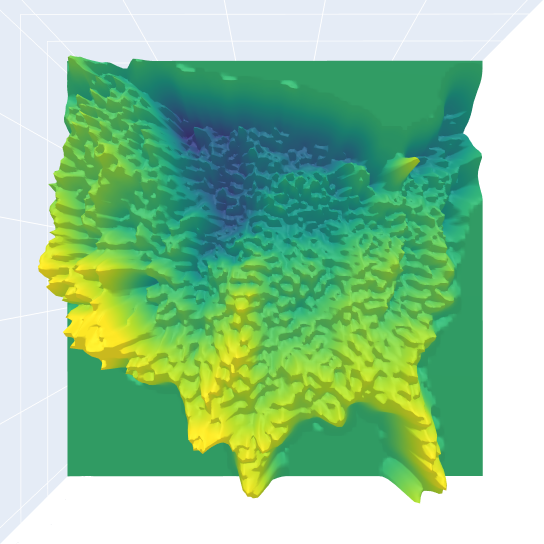
The record-breaking calculation was performed on a dataset composed of daily maximum temperatures (°C) across the United States between 1990 and 2019. (Credit: Marcus Noack, Berkeley Lab)
Using the Perlmutter supercomputer at the National Energy Research Scientific Computing Center (NERSC), Berkeley Lab researchers have devised a new mathematical method for analyzing extremely large datasets – and in the process, demonstrated proof of principle on a record-breaking dataset of more than five million points. Based on a mathematical framework known as Gaussian processes and harnessing the power of high performance computing, the achievement introduces a new tool for machine learning and other fields that deal with massive datasets.
Gaussian processes are part of a family of probabilistic problem-solving methods; they are powerful, flexible, and naturally include a quantification of the degree of uncertainty in their findings, a key element of their predictive power. Exact Gaussian processes bypass sampling and approximation techniques in favor of using complete datasets to make predictions. As a result, they are so computationally expensive and their output so cumbersome to store that they have only been used for small and medium-sized datasets.
A team led by Marcus Noack, a research scientist in the Mathematics for Experimental Data Group at Berkeley Lab, has proposed a new approach to Gaussian processes that takes advantage of datasets’ natural sparsity, making them scalable up to millions of data points while remaining exact. The team’s record-breaking calculation was published in Nature Scientific Reports in March 2023.
Discovering Sparsity
Gaussian processes require the computation, storage, and processing of a large matrix that assigns each pair of points a numerical label describing the relationship between them. However, for most modern datasets, many of those numbers are likely to be zero, meaning there is no relationship between them at all. This new algorithm allows the flexibility to identify those zero entries, ignore them, and only attend to the non-zero numbers – the ones with actual relational value. The resulting matrix of relational values is called the covariance matrix, and identifying and stripping out all zeroes makes it far more efficient to calculate, store, and work with in subsequent computations. This sparser version of the matrix also offers much-improved scalability, and no theoretical limitations to further scaling up have been discovered.
“The novelty of our method is that you only switch out the covariance function that generates the entries in the matrix, and it gives the algorithm the ability to learn that the covariance matrix is naturally sparse,” said Noack. “The premise is that in today’s datasets, this is often the case. You often have a lot of data points, so an algorithm should have the ability to learn that it doesn’t need all that information, and that renders the covariance matrix sparse.”
Notably, this method takes advantage of the data’s own existing qualities rather than using other processes that alter or sub-sample the datasets to try to manufacture such qualities. Competing methods for large-scale Gaussian processes rely on various approximation techniques to manipulate the data.
“All competing methods require you to specify how you want to deal with the size of the matrix ahead of time,” said Berkeley Lab Earth and Environmental Science Area researcher Mark Risser, another author on the paper. “Before you look at your data, you have to come up with a way to approximate this big matrix that has a lot of zeroes in it. Our approach discovers sparsity instead of imposing sparsity upon the data, which is the crux of our method’s novelty – no one’s thought to do that before.”
Embracing Parallelism for Scale
To test and demonstrate their new method with massive datasets, the team needed robust high-performance computing (HPC) resources. Enter Perlmutter, the newly installed supercomputer at NERSC; according to Noack, the record-breaking run wouldn’t have been possible without Perlmutter’s computational power and parallel structure.
The team ran their calculations using gp2Scale, a Python-based program they wrote themselves, which divided the complete matrix into sub-matrices of about 10,000 data points, then sent each to one of Perlmutter’s A100 GPU nodes. The independent nature of the sub-matrices allowed them to be analyzed separately by many nodes working in parallel. When the calculations were complete, gp2Scale canceled out the zero values and stitched the covariance matrix together.
“You would never be able to calculate or store the covariance matrix on any single node or on any computer anywhere,” said Noack. “It only works because it’s distributed. Every GPU only knows its little part and then sends that part back, and a host computer puts it all together.”
Risser said: “GPUs previously have been useless for things related to Gaussian processes: GPUs are good at lots of very small tasks, while the Gaussian process was formerly one big task. This methodology enables one big problem to be split up into a large number of small tasks, which then are really conducive for the GPUs.”
Each calculation of a sub-matrix in the record-breaking run took 0.6 seconds on Perlmutter, down from 15 seconds on Cori, the previous system at NERSC. In total, the record-breaking run of five million data points took about 24 hours using 256 GPUs on Perlmutter – divided into four runs to accommodate the constraints of early access to the system – a fraction of what some other big-data calculations would use.
This drastic reduction in calculation time is part of what makes the method feasible for massive data sets and what makes HPC a crucial part of this new method. “Just two years ago, without access to Perlmutter, this would have looked very different,” said Noack. “Both the math and the computing capacity were necessary. The one really supports the other: the covariance function supports that it can be sparse at all. And then Perlmutter calculates those sparse matrices so fast. So really, both things have had to work hand in hand to make this possible.”
A Tool for Big Data
For the record-breaking run included in their paper, the team applied their scaled-up Gaussian process to a dataset from climate science: daily maximum temperatures (°C) across the United States between 1990 and 2019. (The original dataset contains more than 51 million data points; the team randomly selected just over 5 million of those for demonstration purposes.) Indeed, climate science is one area of study that stands to benefit from the algorithm since sensing technology continues to improve and yield increasingly large amounts of data to be collected, analyzed, and stored.
“In climate research, you have satellites and other remotely sensed sources that are sampling every second in large geospatial footprints, so you end up with millions of data points,” said Risser. “As we gain the ability to monitor the Earth system in different ways, we have larger and larger datasets. New methods and analysis tools that can accommodate massive data volumes while doing things like generating estimates of uncertainty; that’s where the Gaussian process will be a really powerful tool now that we can scale it up in this way.”
Climate science and autonomous experimentation are a subset of the fields that might use this method; a scaled-up Gaussian process could be an important tool for research in any area that deals with high data yields, particularly as machine learning becomes ubiquitous across disciplines and research settings. Other possible areas that might adopt the Gaussian process include mechanical systems modeling (the field that includes robotics) and battery and energy storage technology. Noack notes that it’s in fields where models tend to include some amount of error that Gaussian processes really shine due to the built-in uncertainty quantification.
“This uncertainty is really important for adaptive data-acquisition scenarios because you tend to explore where the error is very large,” he said. “Why would you collect more data where you already know your model very well?”
Building Up
When you’ve invented a new mathematical framework with no theoretical scale limits, where do you go from there?
Noack is working to adapt gp2Scale for other related uses, like a dimensionality-reducing model using machine learning to reduce the complexity of datasets coming from experimental sensors like satellites while including uncertainty quantification.
“There are stochastic methods that can do dimensionality reduction, but they’re hardly ever used, and one of the main reasons is because you can’t do it on a lot of data, and today’s datasets are always large,” he said. “So one of my big goals is to slightly re-implement what we have in gp2Scale now to be able to do this dimensionality reduction in a stochastic way, with the same advantages: You actually get uncertainty intervals. These models will actually be able to tell you, ‘I’m 50% sure that this point is actually here in that low-dimensional space.’” Risser is thinking longer term. In time, he hopes to apply the Gaussian process to a possible stochastic foundation model for climate, a general-purpose machine learning method that could be used and tinkered with for a variety of applications within climate science, incorporating what’s already been observed about the natural world and baking in uncertainty quantification from the start.
“In principle, there are other machine learning methods you could use for such an effort, but again, the Gaussian process is really useful because it incorporates uncertainty,” said Risser. “You could encode in your algorithm a sort of ‘not knowing.’ The global climate system is a very complex thing. We, as climate scientists, know a little bit about it: How does a particle move throughout the atmosphere? What happens in the ocean? Over the last 50 to 100 years, scientists have discovered various differential equations that govern the behavior of the Earth system. Being able to incorporate that sort of physical knowledge into a machine learning method in a way that’s consistent and could be informed by data, I think, gives the Gaussian process a chance of someday accomplishing that goal of a foundation model for Earth sciences.”
In the meantime, Noack believes the next steps are clear: keep scaling up. Because no theoretical barriers to using Gaussian processes for even larger datasets have yet arisen, the sky is currently the limit.
“You can scale further and further up,” Noack said. “If there are any limitations, they’re technical, and those are easier to overcome. So that’s where its strength lies, I think. Our plan is certainly to reach 50 million data points.”
About Berkeley Lab
Founded in 1931 on the belief that the biggest scientific challenges are best addressed by teams, Lawrence Berkeley National Laboratory and its scientists have been recognized with 16 Nobel Prizes. Today, Berkeley Lab researchers develop sustainable energy and environmental solutions, create useful new materials, advance the frontiers of computing, and probe the mysteries of life, matter, and the universe. Scientists from around the world rely on the Lab’s facilities for their own discovery science. Berkeley Lab is a multiprogram national laboratory, managed by the University of California for the U.S. Department of Energy’s Office of Science.
DOE’s Office of Science is the single largest supporter of basic research in the physical sciences in the United States, and is working to address some of the most pressing challenges of our time. For more information, please visit energy.gov/science.