






Software
There are two public versions of HPGMG. Both implement the 4th order (v0.3) solver. The former is MPI+OpenMP3 while the latter adds CUDA support for the key kernels in order to leverage the computing power of NVIDIA's GPUs:
- hpgmg on bitbucket (HPGMG-FV is in the ./finite-volume/source sub directory)
- hpgmg-cuda on bitbucket (v0.3 compliant MPI2+OpenMP3+CUDA7 implementation). Please see NVIDIA's Parallel ForAll blog for more details.
Instructions
A reference MPI+OpenMP implementation of HPGMG-FV is available from bitbucket (source is in the ./finite-volume/source sub directory)...
git clone https://bitbucket.org/hpgmg/hpgmg.git
Compilation of the fourth-order implementation is straightforward requiring specification of the path to the compiler and the appropriate OpenMP flag. For example, on a Cray XC30, one can use...
./configure --CC=cc --CFLAGS="-fopenmp -xAVX" --no-fe
make -j3 -C build
The resultant binary will be placed in ./build/bin/hpgmg-fv. If the configure script fails for some reason (e.g. older version of Python), one can easily compile the code directly.
cd ./finite-volume/source
cc -Ofast -fopenmp -xAVX level.c operators.fv4.c mg.c solvers.c hpgmg-fv.c timers.c \
-DUSE_MPI -DUSE_SUBCOMM -DUSE_FCYCLES -DUSE_GSRB -DUSE_BICGSTAB -o hpgmg-fv
One may run this on 512 sockets of a Cray XC30 running ALPS with MPI+OpenMP using the aprun launcher (mpirun on other platforms...). The example below uses 512 sockets each with 8 x 128^3 boxes (total problem size is 2084^3)
export OMP_NUM_THREADS=12
aprun -n512 -S1 -ss -cc numa_node ./hpgmg-fv 7 8
Note, NERSC's Cray XC30 Edison and Cray XC40 Cori were subsequently upgraded to SLURM. As such, some changes are required to run HPGMG. Below are examples of how to run HPGMG on Edison (2x12 core Ivy Bridge nodes) without exploiting HyperThreading. Note, SLURM can be configured differently from system to system. As such, please use 'verbose' to verify SLURM affinity masks prior to running at scale and change --cpus-per-task accordingly. Note, KMP_AFFINITY must be correctly set to guarantee consistent performance using the Intel Compiler.
#==================================================
# 1 thread per core
# HyperThreading not exploited, but may be enabled in hardware
#==================================================
# n.b. one should remove all instances of 'verbose' when running at scale
# One must explicitly set KMP_AFFINITY to correctly bind all threads used by the Intel OpenMP runtime.
# By default, KMP_AFFINITY(=respect) will inherit the mask defined by SLURM
# (e.g. --cpus-per-task=12 will bind to a socket).
export KMP_AFFINITY=verbose,granularity=core,compact,1
# run HPGMG on 2 nodes (each 2P x 12 cores) using 4, 8, or 16 processes of 12, 6, and 3 OpenMP threads.
export OMP_NUM_THREADS=12
srun --ntasks=4 --ntasks-per-node=2 --cpus-per-task=12 --cpu_bind=verbose,cores ./hpgmg-fv 7 16
export OMP_NUM_THREADS=6
srun --ntasks=8 --ntasks-per-node=4 --cpus-per-task=6 --cpu_bind=verbose,cores ./hpgmg-fv 7 8
export OMP_NUM_THREADS=3
srun --ntasks=16 --ntasks-per-node=8 --cpus-per-task=3 --cpu_bind=verbose,cores ./hpgmg-fv 7 4
NERSC's Cori is a Knights Landing (KNL) based XC40. In order to maximize network bandwidth, it is imperative one compile and run with 2MB pages. In addition, the flux-optimized implementation has shown to be more readily vecotrizable and generally performs much better. Finally, one should tune the tile sizes for the target architecture.
cd ./finite-volume/source
module load craype-hugepages2M
cc -Ofast -xMIC-AVX512 -qopenmp level.c operators.flux.c mg.c solvers.c hpgmg-fv.c timers.c \
-DUSE_MPI -DUSE_SUBCOMM -DUSE_FCYCLES -DUSE_GSRB -DUSE_BICGSTAB -DBOX_ALIGN_JSTRIDE=8 \
-DUSE_MAGIC_PADDING -DBLOCKCOPY_TILE_J=8 -DBLOCKCOPY_TILE_K=128 -o hpgmg-fv
In order to run on KNL, one may need to specify the appropriate constraints (knl quad cache), and one must load the 2MB pages in the batch script. Observe, on Cori, srun's --cpus-per-task argument takes the number of HyperThreads (4x the number of cores).
#==================================================
# 1 thread per core
# HyperThreading not exploited, but may be enabled in hardware
# quadcache KNL
#==================================================
#!/bin/bash -l
#SBATCH -N 8
#SBATCH -o results.hpgmg
#SBATCH -p knl
#SBATCH -C knl,cache
# echo commands to output
set -x
echo $SLURM_JOB_ID
# you must load the 2MB pages before compiling *and* running in order to see the benefit
module load craype-hugepages2M
# n.b. one should remove all instances of 'verbose' when running at scale
# One must explicitly set KMP_AFFINITY to correctly bind all threads used by the Intel OpenMP runtime.
# By default, KMP_AFFINITY(=respect) will inherit the mask defined by SLURM
export KMP_AFFINITY=compact,granularity=thread,1
export KMP_BLOCKTIME=infinite
# in quad cache, it is best to bind to numa node 0
export OMP_NUM_THREADS=8
srun --ntasks=64 --ntasks-per-node=8 --cpus-per-task=32 --cpu_bind=threads numactl -m 0 ./hpgmg-fv 8 1
export OMP_NUM_THREADS=16
srun --ntasks=32 --ntasks-per-node=4 --cpus-per-task=64 --cpu_bind=threads numactl -m 0 ./hpgmg-fv 8 2
export OMP_NUM_THREADS=32
srun --ntasks=16 --ntasks-per-node=2 --cpus-per-task=128 --cpu_bind=threads numactl -m 0 ./hpgmg-fv 8 4
export OMP_NUM_THREADS=64
srun --ntasks=8 --ntasks-per-node=1 --cpus-per-task=256 --cpu_bind=threads numactl -m 0 ./hpgmg-fv 8 8
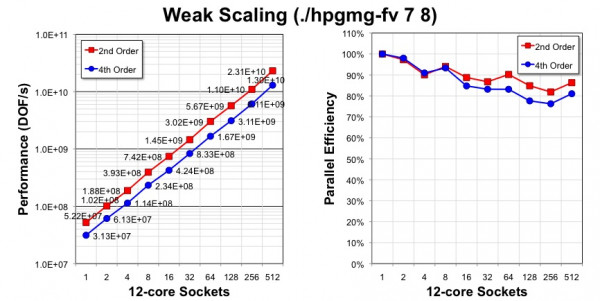
Below is a sampling of both 4th order (v0.3) and 2nd order (v0.2) weak scaling performance and efficiency on Edison. This figure can be used as a basis for performance verification. That is, one should attain similar HPGMG-FV performance and scalability on similar Xeon processor architectures (Nehalem-Haswell). The improvements in residual and error properties more than justify the fact that 4th order performance (DOF/s) is lower than 2nd order.
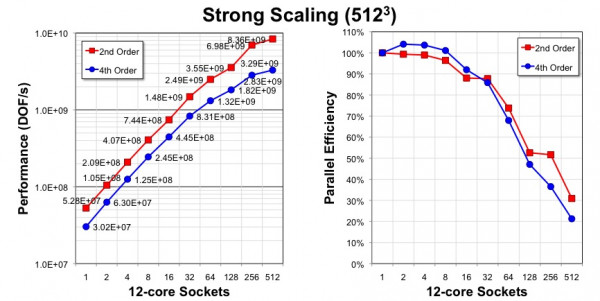
Here, we strong scale a 512³ problem from one socket (12-cores) to 512 sockets (6144 cores). Strong scaling (from one socket) performance and efficiency can be impaired once the problem size becomes so small that performance variability exceeds minimum runtime. Moreover, the 4th order implementation requires exchanging box edges in addition to faces. The current implementation is inefficient in this regard and redundantly transfers both faces and the contained edges. The result is messages that are larger than necessary. As one strong scales, the size of the edges reaches parity with the size of the faces and the message size can be 2x larger than necessary.
There are no NUMA optimizations in HPGMG-FV
Many modern supercomputers are built from 2- or 4-socket compute nodes. These node architectures are almost invariably NUMA (non-uniform memory access). That is, memory bandwidth and latency varies dramatically depending on the locality of data and thread affinity. Many researchers have attempted to optimize codes for these NUMA architectures (e.g. exploiting first touch, leveraging libnuma, etc...). Rather than cluttering the code by attempting to mange NUMA within a process, HPGMG uses MPI to side step all NUMA issues by running (at least) one MPI process per NUMA node. Users should exploit existing mpirun binding and affinity capabilities to bind each process to a NUMA node. For example, when running on a two-socket multicore node (e.g. a system with two 12-core Xeon processors), users should run HPGMG using two processes of 12 threads. On a Cray XC30 like Edison, this is realized via aprun's -S1 -ss -cc numa_node arguments.
GPU-Accelerated Implementation of HPGMG-FV
NVIDIA has released a GPU-accelerated hybrid implementation of the 4th order (v0.3 compliant) version of HPGMG-FV. It has been run on various GPU-accelerated clusters and supercomputers including the Cray XK7 (Titan) at Oak Ridge. Note, CLE 5.2up04 and CUDA 7.0 are recommended when running on a GPU-accelerated Cray. The code may be downloaded via...
git clone https://bitbucket.org/nsakharnykh/hpgmg-cuda.git
One may use ./build.sh (or a custom ./build_titan.sh) to configure and build the resultant MPI+OpenMP+CUDA implementation. As it is a MPI+OpenMP+CUDA implementation, users should select the number of processes and threads and affinity options for their target systems. The benchmark takes the two standard arguments as before.
Questions
Questions regarding HPGMG-FV's implementation, execution, or performance should be directed to Sam Williams.