






Exascale Computing Project Spotlights ExaGraph and STRUMPACK/SuperLU Collaboration
August 29, 2018
Contact: Mike Bernhardt, Bernhardtme@ornl.gov, +1 503.804.1714
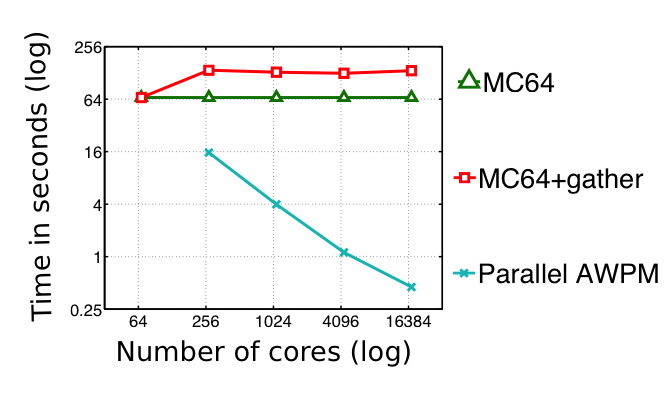
The picture shows the performance of AWPM compared to serial MC64, for a matrix from the plasma fusion device modeling. For this problem, the relative error of the solution is similar with both MC64 and AWPM permutations, but AWPM runs ~300x faster than MC64 on 256 nodes of Cori/KNL. Hence, parallel algorithm and software resulted from this collaboration have successfully removed a sequential bottleneck in SuperLU and STRUMPACK.
Collaboration is key to the success of The Exascale Computing Project (ECP). One recent example of fruitful collaboration within ECP is the teamwork between the Sparse Solvers Software Technology project and the ExaGraph Co-Design Center.
Results of the effort showed that the parallel AWPM (approximate-weight perfect matching) code can run up to 2,500x faster than the sequential algorithm on 256 nodes of the Cori/KNL supercomputer.
This project highlight is based on an interview with members of the Sparse Solvers and ExaGraph Co-Design Center teams.
Research Context
When researchers try to solve science and engineering problems, they often create systems of linear equations that need to be solved. Software libraries known as solvers provide mathematical tools that can be applied to similar problems. Direct solvers that use variants of Gaussian elimination are one of the most popular methods for solving such systems due to their robustness, especially for algebraic systems arising from multiphysics simulations.
In many situations, the system is sparse, meaning that the majority of the matrix entries are zero and ideally need neither to be stored nor operated on. The strength of SuperLU and STRUMPACK is that they can automatically determine which matrix entries are zeros and can be ignored, allowing the computer to focus its calculations on the other entries and finish the problem much faster.
What are the objectives of the ECP Sparse Solvers project and ExaGraph Co-Design Center?
The goal of the Sparse Solvers project is to deliver direct solvers and preconditioners based on two variants of sparse Gaussian elimination: supernodal (SuperLU) and multifrontal (STRUMPACK). Partial pivoting for numerical stability is widely used in dense systems, which at each elimination step, swaps rows to get large elements on the diagonal. In sparse case, this incurs a relatively larger amount of data movement and needs dynamic management of data structures, severely hampering parallel scalability. Instead, SuperLU and STRUMPACK use a static pivoting strategy, in which the matrix is permuted beforehand, so that the largest elements of the input matrix are placed on the diagonal, instead of swapping at runtime.
This is where graph algorithms come into play. Permuting rows of a sparse square matrix can be formulated as a matching problem on a bipartite graph. Until recently, SuperLU used robust but serial bipartite matching code named MC64 for this task. There have been several attempts to develop parallel versions of MC64 in the past, but they were either severely limited in scalability or were not robust enough to be used in production.
The ExaGraph Co-Design Center investigates a diversity of data analytic computational motifs, including graph traversals, graph matching and coloring, graph clustering and partitioning, parallel mixed-integer programs, and ordering and scheduling algorithms. The ExaGraph team recently made a breakthrough in scalable algorithm design for weighted bipartite matching problems. The team developed a novel two-step method that is more scalable than the previous attempts: first, generate a perfect matching in parallel such that diagonal is free of zero entries, and secondly, search for weight-augmenting cycles of length four in parallel and iteratively augments the matching with a vertex disjoint set of such cycles, while still maintaining a perfect matching. The algorithm is named AWPM (approximate-weight perfect matching) and has many applications in addition to sparse Gaussian elimination.
How would you describe the nature of the collaboration/teamwork involved?
The members of the ExaGraph team had previously developed distributed memory perfect matching algorithms but such algorithms had not maximized the weight of the matching. With the funding from ECP and the collaborative environment it provided, the ExaGraph team and the Factorization-Based Sparse Solvers team decided to make the solution of this problem a joint milestone. The new effort focused on turning a perfect matching into an approximate maximum-weight perfect matching so that it can be used for stable pivoting in SuperLU and STRUMPACK.
What is the impact of the accomplishment in terms of furthering the move to exascale?
We conducted extensive experiments on the Edison and Cori machines at NERSC. For most practical problems (over 100 sparse matrices with dimension larger than 0.5M, from DOE applications and SuiteSparse), the weights of the perfect matchings generated by AWPM are within 99% of the optimum solution. As a result, AWPM works as good as the optimum algorithm for most matrices when used with SuperLU to prepermute the matrix.
This close collaboration between the two teams led to the following joint publication and software products.
- A. Azad, A. Buluc, X.S. Li, X. Wang, J. Langguth, “A Distributed-Memory Approximation Algorithm for Maximum Weight Perfect Bipartite Matching,” arXiv:1801.09809v1, 30 Jan 2018.
- Software integration: we have implemented an interface in SuperLU and STRUMPACK that takes the AWPM code as a pre-ordering option. This new option is publicly available in the Master branch of GitHub repos and will be in the upcoming tarball releases.
- The AWPM code is freely distributed as part of the Combinatorial BLAS library.
Researchers
 Xinliang Wang (Tsinghua University) Xinliang Wang (Tsinghua University) |

 Ariful Azad (Berkeley Lab)
Ariful Azad (Berkeley Lab) Aydin Buluc (Berkeley Lab)
Aydin Buluc (Berkeley Lab) Pieter Ghysels (Berkeley Lab)
Pieter Ghysels (Berkeley Lab) Johannes Langguth (Simula)
Johannes Langguth (Simula)More information: https://www.exascaleproject.org/exagraph-with-strumpack-superlu/
About Berkeley Lab
Founded in 1931 on the belief that the biggest scientific challenges are best addressed by teams, Lawrence Berkeley National Laboratory and its scientists have been recognized with 16 Nobel Prizes. Today, Berkeley Lab researchers develop sustainable energy and environmental solutions, create useful new materials, advance the frontiers of computing, and probe the mysteries of life, matter, and the universe. Scientists from around the world rely on the Lab’s facilities for their own discovery science. Berkeley Lab is a multiprogram national laboratory, managed by the University of California for the U.S. Department of Energy’s Office of Science.
DOE’s Office of Science is the single largest supporter of basic research in the physical sciences in the United States, and is working to address some of the most pressing challenges of our time. For more information, please visit energy.gov/science.