






‘Data Deluge’ Pushes Mass Spectrometry Imaging to New Heights
MANTISSA Takes Novel Approach to Improve Data Analysis for Advanced Imaging Tools
July 15, 2015
Contact: Kathy Kincade, +1 510 495 2124, kkincade@lbl.gov
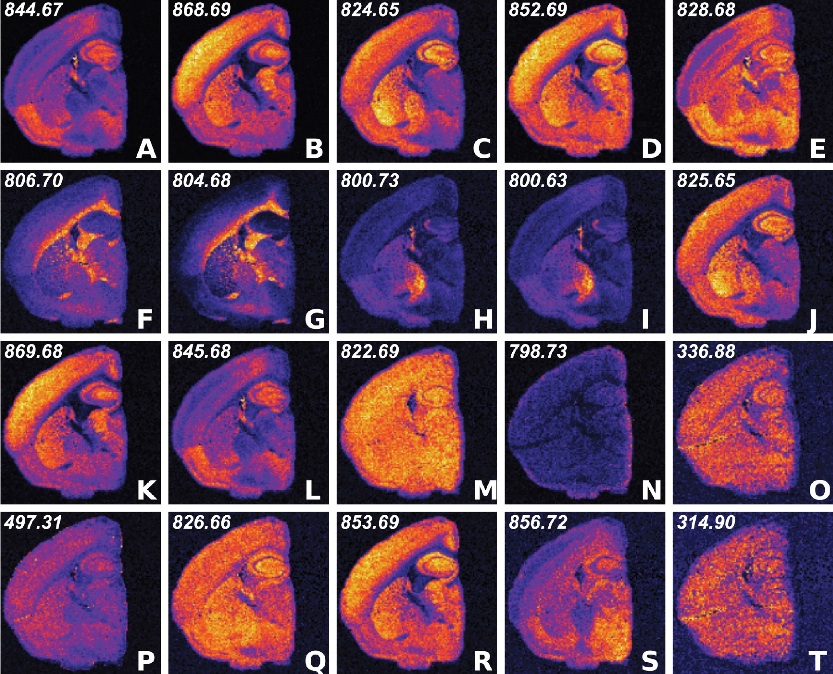
Ion-intensity visualization of the 20 most important ions in a mouse brain segment selected by the CX/CUR algorithm. Of the 20 ions, little redundancy is present, pointing to the effectiveness of the CX approach for information prioritization. Image: Ben Bowen, Lawrence Berkeley National Laboratory
Researchers at Berkeley Lab are combining mathematical theory and scalable algorithms with computational resources at the National Energy Research Scientific Computing Center (NERSC) to address growing data-management challenges in climate research, high-energy physics and the life sciences.
Scalable statistics and machine-learning algorithms are essential for extracting insights from big data, including the increasingly massive datasets being generated by advanced imaging tools used in astronomy, genomics, climate studies and the life sciences. To develop better methods for analyzing these datasets, in 2014 Berkeley Lab launched a project dubbed MANTISSA (Massive Acceleration of New Technologies in Science with Scalable Algorithms). Funded through a Department of Energy ASCR applied math grant, MANTISSA supports the development of novel algorithms that will allow new software tools in a variety of science domains to run at scale on NERSC’s current and next-generation supercomputers.
“The MANTISSA grant has enabled us to bring together leading researchers from UC Berkeley, Stanford, Harvard and MIT to work on some of the leading challenges we face in experimental and observational sciences at NERSC,” said Prabhat, who leads NERSC’s Data and Analytics Services team and is a PI for the MANTISSA grant. “Very often, researchers in the fields of statistics and machine learning work on a canonical set of ‘big data’ problems in industry—such as image search and speech recognition—but in this instance we’ve successfully engaged them to work on high-profile, high-impact science problems.”
MANTISSA’s first order of business was to improve data analysis in mass spectrometry imaging (MSI), widely used in the life sciences for studying tissues, cell cultures and bacterial colonies and in clinical diagnostics for screening and diagnosing disease and metabolic disorders, monitoring drug therapy, identifying drug toxicity and poisoning and discovering new biomarkers. Datasets from MSI provide unprecedented characterization of the amount and spatial distribution of molecules in a sample, leading to detailed investigations of metabolic and microbial processes at subcellular to centimeter resolutions.
But this accuracy comes at a price: the raw datasets range from gigabytes to terabytes in size, which can be a challenge for even large computing systems to wade through efficiently.
“If you think about an MSI file, it has about the same amount of data as a stack of books a mile tall, and it would take a person their entire life to go through every peak and pixel,” said Ben Bowen, a scientist in Berkeley Lab’s Life Sciences Division and Application Lead on OpenMSI, a cloud-based platform hosted at NERSC that allows MSI data to be viewed, analyzed and manipulated in a standard web browser. “It’s not realistic."
Needles in a Haystack
In a typical MSI experiment, key ions are singled out from the MSI images to identify critical compounds and their locations in those images. To simplify this process, researchers use mathematical techniques—such as non-negative matrix factorization (NMF) and principle component analysis (PCA)—to reduce the volume of data generated in an MSI dataset. However, these techniques have a key drawback: the combinations of data elements they return can be hard to interpret, particularly if you are looking for a specific ion or ion location.
“NMF and PCA are great tools for identifying characteristic differences in big, multidimensional MSI datasets,” said Bowen, who collaborates regularly with Berkeley Lab’s Northen Lab, which uses MSI to study metabolic processes in complex cellular systems. “But oftentimes what you need is to zero in on the most important location and the most important ion in an image.”
Enter randomized linear algebra (RLA), a mathematical technique commonly used in engineering, computational science and machine learning problems such as image processing and data mining. Through MANTISSA, mathematicians from Stanford University and UC Berkeley joined forces with the OpenMSI team to see if two RLA algorithms—CX and CUR—might make it easier to pinpoint specific data points in an MSI file.
In a study published May 31 in Analytical Chemistry, Prabhat, Bowen and Michael Mahoney, adjunct professor in the Department of Statistics at UC Berkeley, ran CX and CUR computations on NERSC’s Edison system using two OpenMSI datasets: mammalian brain and lung sections. They found that using these algorithms streamlined the data analysis process and yielded results that were easier to interpret because they prioritized specific elements in the data. For Bowen, who is currently focused on imaging microbial reactions in an environmental context, this approach could more rapidly and accurately identify key metabolites in these reactions.
“CX/CUR is an efficient algorithm for identifying locations and compounds in large data sets, and it brings the unique capability of giving you a list of ranked chemicals, compounds and locations in terms of their importance,” said Bowen. “Previous methods would provide ensembles of locations and compounds, and follow-up studies were required to locate them.”
In addition, the CX/CUR algorithms are highly scalable to larger datasets and applications outside of MSI, whereas the clustering-based methods are not, Mahoney emphasized.
“One of the reasons we were interested in these methods was we knew they would scale up to data literally 1,000 to 10,000 times larger,” he said. “All sorts of PCA-based methods have been developed in the last few years, but our algorithms will scale up to terabyte-size data and larger, which greatly expands the breadth of potential applications.”
Looking ahead, the researchers will apply CX/CUR to terabyte-size and larger datasets where traditional PCA-based methods can’t be applied and will test the algorithms in other science domains, including climate research and high-energy physics.
“One of the challenges that people are facing these days is that all these data come from lots of different application areas,” Mahoney said. “Scientists typically develop a method for one application area that is very finely tuned for that area but hard to port to other areas. So what we need is to get a set of principled algorithmic methods that work with small scale but also very, very large scale data and that are useful in a range of different application areas.”
This study demonstrates how a mathematical theory such as randomized linear algebra can be combined with one of the most sophisticated imaging modalities in life sciences to further scientific progress, added Prabhat. “In my opinion, it is the perfect success story for MANTISSA.”
About Berkeley Lab
Founded in 1931 on the belief that the biggest scientific challenges are best addressed by teams, Lawrence Berkeley National Laboratory and its scientists have been recognized with 16 Nobel Prizes. Today, Berkeley Lab researchers develop sustainable energy and environmental solutions, create useful new materials, advance the frontiers of computing, and probe the mysteries of life, matter, and the universe. Scientists from around the world rely on the Lab’s facilities for their own discovery science. Berkeley Lab is a multiprogram national laboratory, managed by the University of California for the U.S. Department of Energy’s Office of Science.
DOE’s Office of Science is the single largest supporter of basic research in the physical sciences in the United States, and is working to address some of the most pressing challenges of our time. For more information, please visit energy.gov/science.