






Meeting the Computing Challenges of Next-Generation Climate Models
Berkeley Lab hosts international workshop as climate scientists find themselves in a deluge of data
March 26, 2013
JHChao@lbl.gov +1 510 486 6491
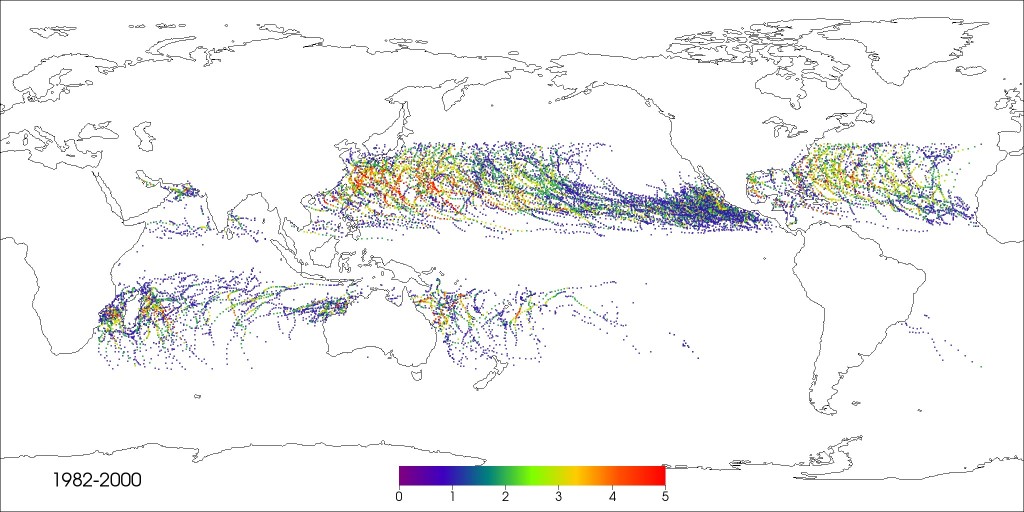
A computer simulation of hurricanes from category 1 through 5 over 18 years generated nearly 100 terabytes of data.
Remember when a megabyte (106 bytes) seemed like a lot of data? Then a gigabyte (109) became routine. Now terabytes (1012) are small potatoes, and scientists—especially climate scientists—are increasingly processing datasets that involve petabytes (1015) of data. Even for the world’s fastest supercomputers, that can be a long, hard workout.
As global climate models improve, they are generating ever larger amounts of data. For Michael Wehner, a climate scientist in the Computational Research Division of Lawrence Berkeley National Laboratory (Berkeley Lab) who focuses on extreme weather—such as the intense hurricanes, “derecho” and atmospheric rivers (or “pineapple express”) like the one that California saw last December—computing challenges are key to his work.
“In order to simulate these kinds of storms, you really do need high-resolution climate models,” he said. “A model run can produce 100 terabytes of model output. The reason it’s so high is that in order to look at extreme weather you need high-frequency data. It’s a challenge to analyze all this data.”
For Wehner, a dataset that would take 411 days to crunch on a single-processor computer takes just 12 days on a Hopper, a massively parallel supercomputer at the National Energy Research Scientific Computing Center (NERSC) at Berkeley Lab. Despite this advance, Wehner feels it should take only about an hour.
Berkeley Lab recently hosted an international workshop that brought together top climatologists, computer scientists and engineers from Japan and the United States to exchange ideas for the next generation of climate models as well as the hyper-performance computing environments that will be needed to process the data from those models. It was the 15th in a series of such workshops that have been taking place around the world since 1999.
“The Japanese have big machines, as does the U.S.,” Wehner said. “They’re also leaders in high-performance computing for climate science.”
Experts from other U.S. Department of Energy (DOE) national labs, as well as scientists from Germany, the UK and other U.S. research institutions also attended the three-day event.
Wehner offered an example of getting completely opposite results when running simulations with a lower-resolution climate model versus a high-resolution version of the same model. “My conclusion from a 100-kilometer model is that in the future we will see an increased number of hurricanes, but from this more realistic simulation from the 25-kilometer model, we draw the conclusion that the total number of hurricanes will decrease but the number of very intense storms will increase.”
So how will computers keep up with this deluge of data? The answer: exascale computing (a quintillion, or 1018, computer operations per second), a thousand-fold increase over current petascale systems. John Shalf, Berkeley Lab researcher and also Chief Technology Officer of NERSC, is leading an effort to achieve exascale performance.
“We need to rethink our computer design,” Shalf told workshop attendees. “Data explosion is occurring everywhere in the Department of Energy—genomics, experimental high energy physics, light sources, climate.”
After decades of exponential growth in computing power, including improvements in memory density and parallelism, which drove down the cost of computing performance, or FLOPS (floating point operations per second), a different constraint is starting to emerge, the cost of moving data across a chip. So factors that used to be the most important in designing a computer will soon become the least important. “In 2018 the cost of FLOPS will be among the least expensive aspects of a machine, and the cost of moving data across the chip will be the most expensive,” Shalf said. “That’s a perfect technology storm.”
Shalf outlined several DOE initiatives that are trying to tackle the challenge, partly by fundamentally changing the way computers are designed. For example, a continuous feedback loop between the hardware designers and software designers used to take about six years to complete a design cycle. “We’re trying to develop processes where this loop can happen on a weekly basis,” he said.
To do that, engineers are using predictive modeling of hardware to predict performance of exascale systems. “We’re simulating hardware before it is built,” Shalf said.
With better hardware tools as well as software tools, climate scientists will be able to perform analyses that were previously impossible. For example, they now have a better understanding of the relationship between model resolution and accuracy of reproducing extreme weather events. They are also able to better detect, analyze and characterize extreme events.
“Datasets are getting larger, but there’s more interesting science and physics hidden in the data, which creates opportunities for asking more questions,” said Berkeley Lab scientist Wes Bethel, who heads a visualization group in the Computational Research Division. “Tools of yesteryear are incapable of answering these questions on climate.”
About Berkeley Lab
Founded in 1931 on the belief that the biggest scientific challenges are best addressed by teams, Lawrence Berkeley National Laboratory and its scientists have been recognized with 16 Nobel Prizes. Today, Berkeley Lab researchers develop sustainable energy and environmental solutions, create useful new materials, advance the frontiers of computing, and probe the mysteries of life, matter, and the universe. Scientists from around the world rely on the Lab’s facilities for their own discovery science. Berkeley Lab is a multiprogram national laboratory, managed by the University of California for the U.S. Department of Energy’s Office of Science.
DOE’s Office of Science is the single largest supporter of basic research in the physical sciences in the United States, and is working to address some of the most pressing challenges of our time. For more information, please visit energy.gov/science.